用公共数据库数据不做实验也能发五分以上文章套路
事实上很多院校对SR、OT都嗤之以鼻,但是今年oncotarget竟然逆势上涨,小编又不小心关注了一下,刚好看到一篇比较简单适合新手入手的文章,今天就来聊一聊这篇不做实验依然发五分以上文章的套路。
这篇文章是去年十月份发表在oncotarget上的题目是:A seven-gene signature predicts overall survival of patients with colorectal cancer

文章主要流程如下:
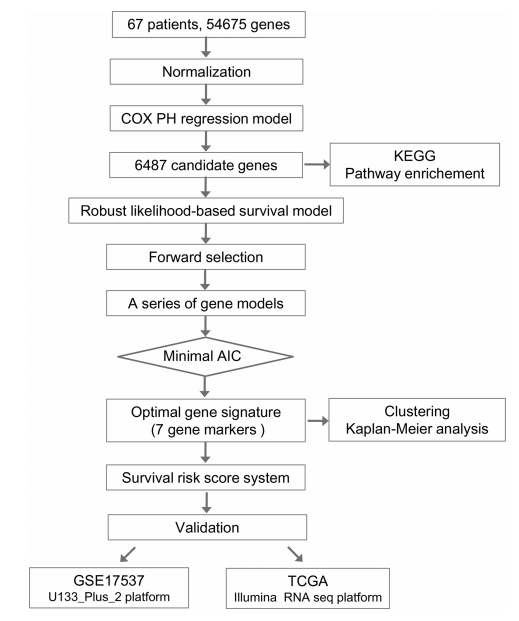 从流程中来看其实非常简单,就是先下载67个样本的芯片数据,做数据标准化,跑了一下单因素生存分析,筛选出了6487个显著的基因 (探针),进一步做了一下KEGG的富集美化了一下结果,然后使用一个降维工具(有个R包,一条命令就完事),筛选出了7个基因,这七个基因能够区分癌症高风险低风险,然后建立了这样的7个基因的预后模型,随后用TCGA、GSE17537两套数据来验证了一下这个模型的好坏,就完事了。
从流程中来看其实非常简单,就是先下载67个样本的芯片数据,做数据标准化,跑了一下单因素生存分析,筛选出了6487个显著的基因 (探针),进一步做了一下KEGG的富集美化了一下结果,然后使用一个降维工具(有个R包,一条命令就完事),筛选出了7个基因,这七个基因能够区分癌症高风险低风险,然后建立了这样的7个基因的预后模型,随后用TCGA、GSE17537两套数据来验证了一下这个模型的好坏,就完事了。
看完这些有些R语言好一点的同学自己就能做了,是不是突然发现原来五分的文章这么好发,事实上建模的文章没有发不出去的,只有不会写文章的人。
那么怎么将上述结果整理成一篇有逼格的文章是一个技术活,现在一步一步来解析这篇文章
1、首先数据下载及标准化先说明
2、其次单因素生存分析,显著差异的说明一下,顺带列个最显著的前20个放在文章表里(这篇文章没放)
3、这些显著的预后差异基因的KGEE富集结果简要说明一下这些结果,不局限与KEGG,GO等其他的也行,主要丰富文章内容,说明这些预后差异基因跟肿瘤有有什么联系
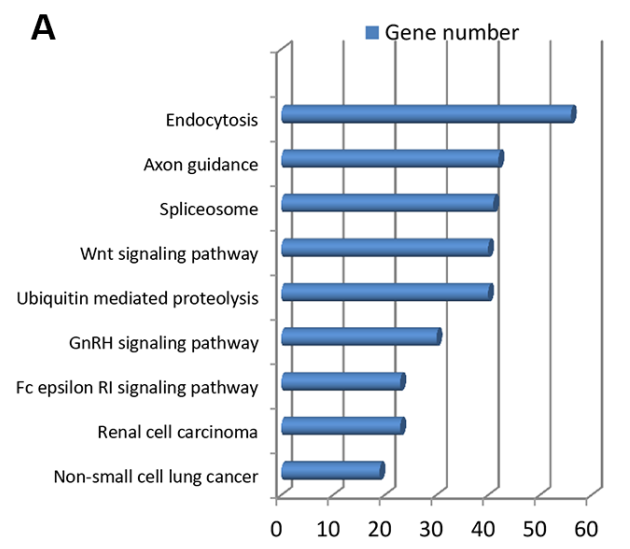
4、开始降维,得到降维结果,降维方法很多,这里用的是rbsurv,可以换lasso,unicox等等很多降维方法,也可以多次,多参数的使用同一种降维方法进行降维
5、得到最终的降维后的基因集
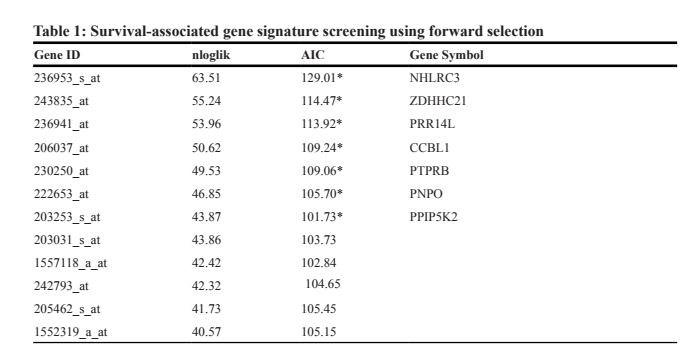
7、这些基因集的特征分析如图B、C、D,主要就几个方面每个基因的单因素、多因素、差异表达(早期和晚期,癌与癌旁等等)、聚类分析、聚类后的样本预后分析,这些可以都尝试一遍找到想要的结果,本文中使用的是聚类分析,聚类后分类预后差异显著,同时大部分基因在正常与癌症组织中差异表达,用来说明这7个基因确实能够影响疾病的预后
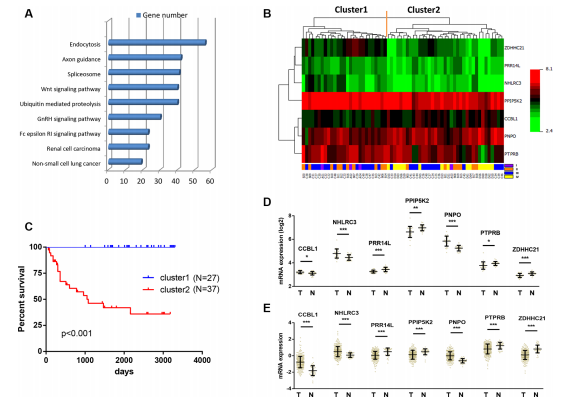
8、建立多因素预后模型,这是本文的最终的模型结果,自己做不局限于此,可以根据第七步的结果酌情选择最终的建模方法,这里简单粗暴的使用的多因素回归,从AUC结果可以看出结果很好
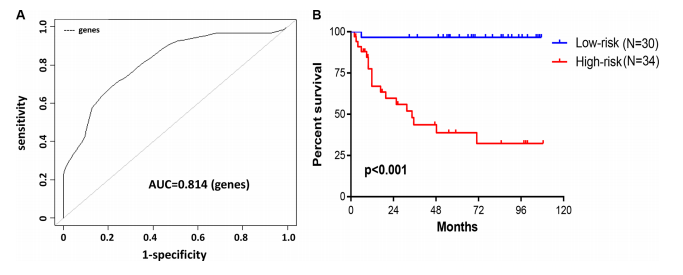 9、既然预后模型已经建完,那么咱们就该来对比一下这个模型与现在的TNM分期等有什么关系,效果会不会比他们好一点,显然结果好就往上贴(你懂的)
9、既然预后模型已经建完,那么咱们就该来对比一下这个模型与现在的TNM分期等有什么关系,效果会不会比他们好一点,显然结果好就往上贴(你懂的)
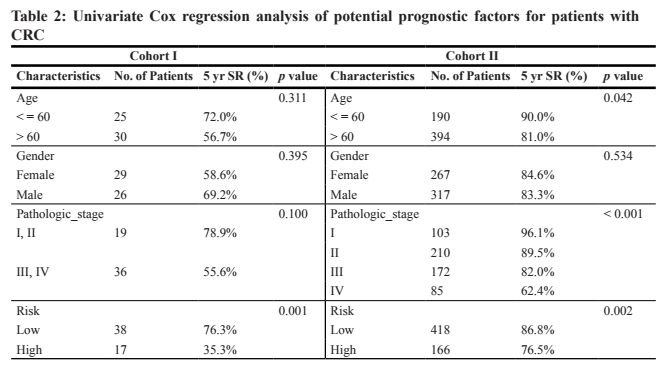 10、外部数据集验证,先TCGA数据来验证一下,当你的数据TCGA中没有怎么办?很简单!在你刚开始的时候把样本分组,分一部分数据到这里来,或者随机抽样。
10、外部数据集验证,先TCGA数据来验证一下,当你的数据TCGA中没有怎么办?很简单!在你刚开始的时候把样本分组,分一部分数据到这里来,或者随机抽样。

至此一篇有态度的文章结束,虽然简单粗暴,但你却无法反驳,当然学术研究必然是严谨的,作者做这篇文章中也一定尝试了很多方法,给我们呈现了一个7-gene模型,同时也给我们提供了一个数据建模思路。
- 发表于 2017-06-26 16:35
- 阅读 ( 15788 )
- 分类:软件工具
