UCSC上的数据是经过处理的,而TCGA上的是最原始的。
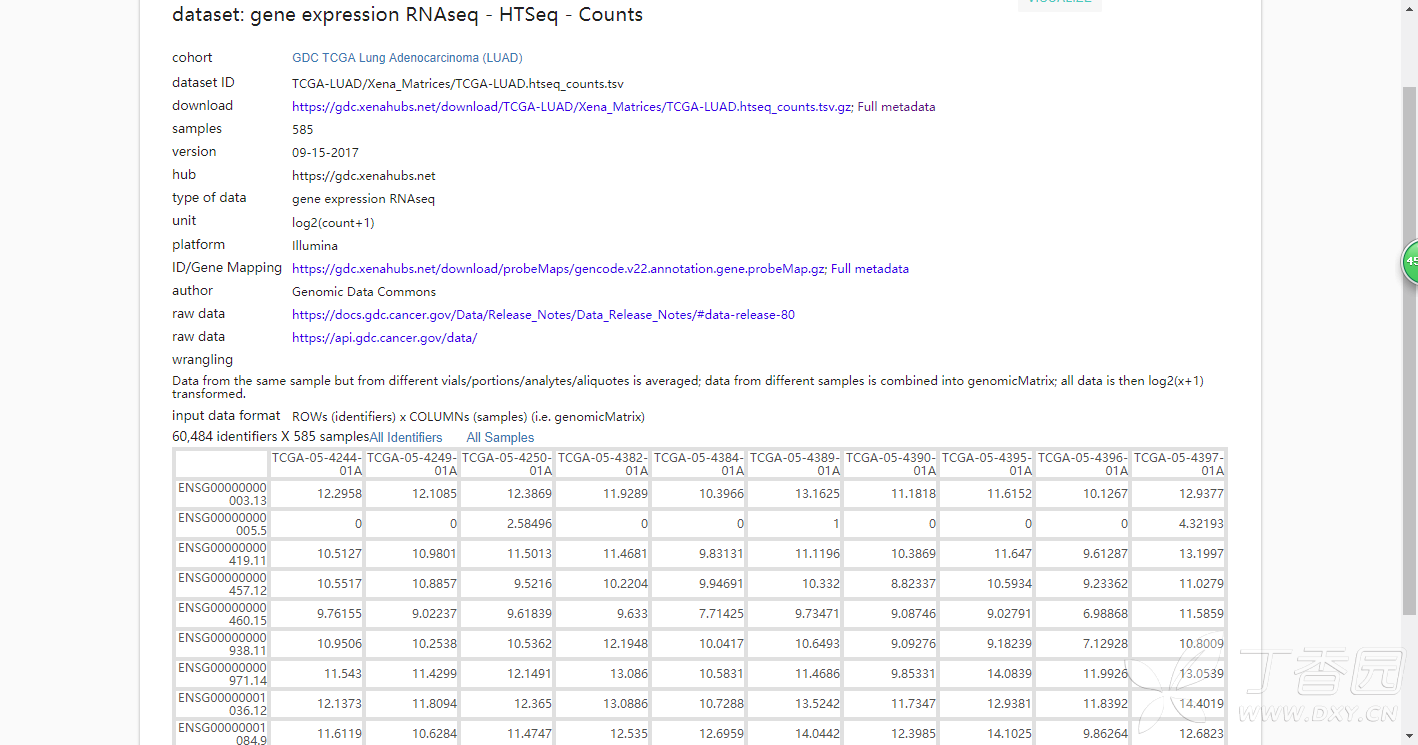
60,484行,每一行似乎是一个ENSG基因编码:这是60484个转录本,UCSC上的两万来个是编码基因的表达谱,是从这60484个转录本里面提取出来的子集。
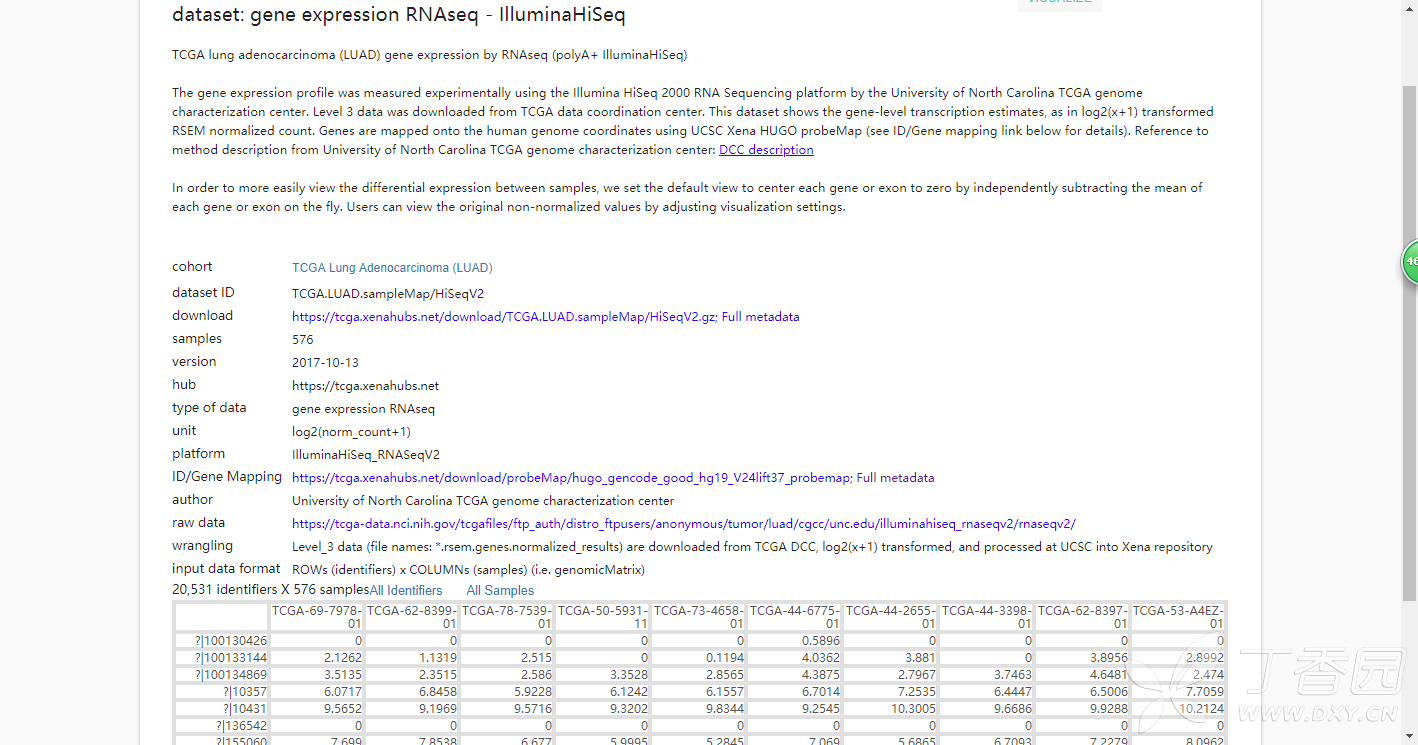
RSEM处理过的数据:这是TCGA老版本使用的RNASeq数据的定量方法,这里的数据也是来源于老版本的,新版TCGA统一使用Counts、FPKM来定量,故有一些差别,两种数据都可以用,看你自己的需求。
在https://xenabrowser.net/中我发现了两种格式不太一样的TCGA数据
以luad数据集举例
第一种是
dataset: gene expression RNAseq - HTSeq - Counts
这个有60,484行,每一行似乎是一个ENSG基因编码,是count数据,类似的还有FPKM和FPKM-UQ
另外一种是
dataset: gene expression RNAseq - IlluminaHiSeq
这个只有20,531行,似乎是用RSEM处理过的数据,每行是基因名称
我不太了解它们两个的区别和关系,适合在何种情况下使用(差异分析很多需要count数据这个我知道),事实上我现在需要重构癌症模型,不知道该使用哪一种,希望各位不吝赐教,我对于生物概念不是特别了解,下面附上数据的网址: