生信人值得拥有的编程模板-Perl
为什么要学编程

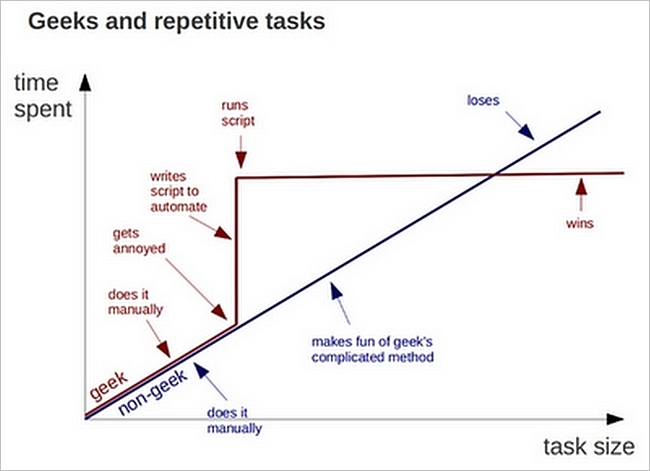
图1. 重复工作任务量与时间关系[1]
如上图,对于大量重复工作,非编程者(non-geek)工作量和时间是正相关的,就像富士康流水线上的工人,这种工作对于高智商的人是无法忍受(富士康招流水线工人会测智商,高智商不会被分配大量重复工作,容易离职)。而编程者(geek)会分三个阶段:手工操作摸索规律(与non-geek效率相同)、编写程序(被non-geek远远甩开)、运行程序(秒杀non-geek)。
生物信息就是这样一门科学,让重复工作远离人工重复劳动。即使非生信人员,学点编程,在生活中也是非常有乐趣的。
生物信息领域常用语言
个人认为:是否能熟悉使用Shell(项目流程搭建)+R(数据统计与可视化)+Perl/Python等(胶水语言,数据格式转换,软件间衔接)三门语言是一位合格生物信息工程师的标准。
生物信息常用语言非常广泛,我常用的有Perl, R, Shell,此外参与网页制作还用过PhP+mySQL,写公众号/博客通用Markdown。这些其实都是非常小众的语言,如果和计算机专业的人交流,对方可能没听过这些语言。本系列“生信人值得拥有的写作模板”主要以Perl为主,并伴随一些零星的R和Shell编程的经验和技巧。对于生信Perl使用人员有个交流和互相提高的平台,让新人少走点弯路。对于没有任何Perl基础强例建议别入坑,直接学Python教程吧,不解释看下图。

我们可以看到世界前三是Java, C, C++,大家都听说过;第五是Python,目前在生领领域有取代Perl地位的趋势,目前Perl列第12(比去年同期又下降三位)。R语言的数据分析领域有应用越来越广泛,今年上升三位至15名;Shell由于版本和各类较多,在50-100名间有4种,此语言只建议快速解决小问题,不建议写太长的任务,很容易跨平台不兼容。
总结:
- 生信常用语言:Shell+R+Python/Perl
- 世界三大语言:Java, C, C++
- 生信语言的排名:Python 5th 稳定 , Perl 12th 快速下降, R 15th 快速上升
Perl语言简介
Perl,一种功能丰富的计算机程序语言,运行在超过100种计算机平台上,适用广泛,从大型机到便携设备,从快速原型创建到大规模可扩展开发。 Perl最初的设计者为拉里·沃尔(Larry Wall),于1987年12月18日发表。现在的版本为Perl 6,于2015年12月25日更新。 Perl借取了C、sed、awk、shell 脚本语言以及很多其他程序语言的特性,其中最重要的特性是它内部集成了正则表达式的功能,以及巨大的第三方代码库CPAN。简而言之,Perl像C一样强大,像awk、sed等脚本描述语言一样方便,被Perl语言爱好者称之为“一种拥有各种语言功能的梦幻脚本语言”、“Unix 中的王牌工具”。 Perl 一般被称为“实用报表提取语言”(Practical Extraction and Report Language),你也可能看到“perl”,所有的字母都是小写的。一般,“Perl”,有大写的 P,是指语言本身,而“perl”,小写的 p,是指程序运行的解释器。[1]
Perl写作环境模板推荐

很多人三行两行或直接命令行用perl直接解决问题,虽然快,但是不容重用和别人使用。因此,良好的写作环境和模板是效率和专业的体现,即提高自己的代码重用性,也方便交流和他人使用。
编程环境IDE
推荐使用:Editplus 4.0,网上到处都是注册机和序列号,随便用,下载址搜不到好用的。可以后台回复“editplus”获得下载链接。此软件优点是可配置模板,可直接编辑服务器脚本(省略上传步骤),高效的代码调试。
编程模板
下面代码为实现常用功能的写作模板,如帮助文档部分(提高代码重用和版本管理,方便其他人使用),命令行参数管理(可读性的命令行是程序的基础),程序运行时间统计(项目时间管理),常用文件读取数据结构样式(方便修改文件输入和输出)等;
下面是实现这样功能的模板:可复制代码,在editplus中保存为template.pl文件。每步有详细的注释,仔细看看吧。
#!/usr/bin/perl -w
# 加载时间管理,参数管理,文件名和路径处理的基础包,无须安装
use POSIX qw(strftime);
use Getopt::Std;
use File::Basename;
###############################################################################
#Scripts usage and about.
# 程序的帮助文档,良好的描述是程序重用和共享的基础,也是程序升级和更新的前提
###############################################################################
sub usage {
die(
qq!
Usage: template.pl -i inpute_file -o output_file -d database -h header num
Function: Template for Perl
Command: -i inpute file name (Must)
-o output file name (Must)
-d database file name
-h header line number, default 0
Author: Liu Yong-Xin, liuyongxin_bio\@163.com, QQ:42789409
Version: v1.0
Update: 2017/10/8
Notes:
\n!
)
}
###############################################################################
#命令行参数据的定义和获取,记录程序初始时间,设置参数默认值
#Get the parameter and provide the usage.
###############################################################################
my %opts;
getopts( 'i:o:d:h:', \%opts );
&usage unless ( exists $opts{i} && exists $opts{o} );
my $start_time=time;
print strftime("Start time is %Y-%m-%d %H:%M:%S\n", localtime(time));
print "Input file is $opts{i}\nOutput file is $opts{o}\n";
print "Database file is $opts{d}\n" if defined($opts{d});
# 调置参数的初始值,可以添加更多参数的默认值
$opts{h}=1 unless defined($opts{h});
###############################################################################
#读入的数据或注释文件,用于与输入文件比较或注释(可选),提供三种方式
#Read the database in memory(opt)
###############################################################################
#open DATABASE,"<$opts{d}";
# 1. 散列结构数据库,要求数据文件有唯一ID并且无顺序要求
#my %database; #database in hash
#while (<DATABASE>) {
# chomp;
# my @tmp=split/\t/;
# $database{$tmp[1]}=$tmp[2];
#}
# 2. 数组结构数据库,无唯一ID,但有顺序要求
#my (@tmp1,@tmp2); #database in array
#while (<DATABASE>) {
# chomp;
# my @tmp=split/\t/;
# push @tmp1,$tmp[1];
# push @tmp2,@tmp[2];
#}
#close DATABASE;
# 3. 批量数据文件,读取一批有相似结构的文件
#open a list file
#my %list;
#my @filelist=glob "$opts{i}";
#foreach $file(@filelist){
# open DATABASE,"<$file";
# $file=basename($file);
# while (<DATABASE>) {
# my @tmp=split/\t/;
# $list{$file}{nr}++;
# }
# close DATABASE;
#}
###############################################################################
#Main text.
###############################################################################
# 正文部分,读取输入文件,列出输入和输入文件的三行作为示例,方便编程处理数据
open INPUT,"<$opts{i}";
#chrm0 snppos1 ref2 mat_gtyp3 pat_gtyp4 c_gtyp5 phase6 mat_all7 pat_all8 cA9 cC10 cG11 cT12 winning SymCls SymPval BindingSite cnv
#1 4648 C A C M PHASED C A 0 11 0 0 M Asym 0.0009765625 -1 0.902113
open OUTPUT,">$opts{o}";
#chrm snppos ref mat_gtyp pat_gtyp c_gtyp phase mat_all pat_all cA cC cG cT winning SymCls SymPval BindingSite cnv
#1 4648 C A C M PHASED C A 0 11 0 0 M Asym 0.0009765625 -1 0.902113
my %count;
# h参数用于去除有文件头的行
while ($opts{h}>0) { #filter header
$tmp=<INPUT>;
$opts{h}--;
# 可选,输出文件也保留文件头
#print OUTPUT $tmp;
}
# 输入和输入处理部分,常用按行读取处理并输入,默认按tab分割数据
while (<INPUT>) {
chomp;
my @tmp=split/\t/;
print OUTPUT "$tmp[0]\t$tmp[1]\n";
}
close INPUT;
close OUTPUT;
###############################################################################
#Record the program running time!
# 输出程序运行时间
###############################################################################
my $duration_time=time-$start_time;
print strftime("End time is %Y-%m-%d %H:%M:%S\n", localtime(time));
print "This compute totally consumed $duration_time s\.\n";
模板导入Editplus
将上述代码保存为template.pl,在editplus中选择Tools -- Preference -- Template -- Perl,点击template.pl右边的..按键,选择你自己的template.pl即可,以后选择perl脚本会自己加载该模板。 希望对大家有帮助!
Reference
- 发表于 2017-10-13 20:03
- 阅读 ( 5083 )
- 分类:编程语言

{kind=link}