KaplanMeier生存曲线绘制工具
在临床研究中,生存曲线(又称Kaplan-Meier曲线)是最常用图片之一,旨在描述各组患者的生存状况。一张漂亮的、专业的生存曲线图不仅可以令编辑、读者和审稿专家眼前一亮,同时也能为论文增色不少。然而,对于一些新手而言,生存曲线却显得十分陌生,不知道为何要绘制生存曲线,也不知道该如何解读生存曲线的结果。在这里我们基于R软件包survival开发了在线版本的 KaplanMeier生存曲线绘制工具。
本工具 支持 分组变量的 生存曲线绘制,也支持 连续型变量的生存曲线绘制,输入数据 为三列【时间、生存状态、分组因素】
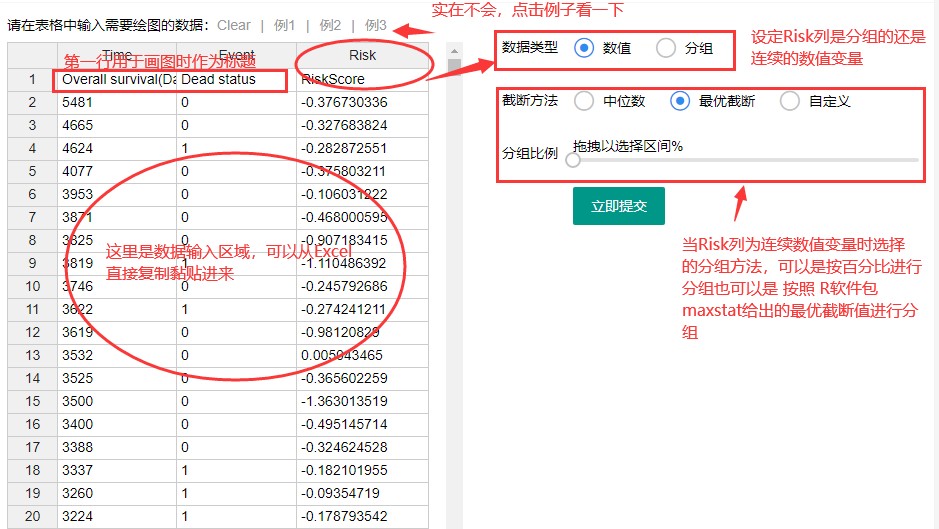
输入数据就是这么简单明了,一眼就会,接下来是图片的调整,也是一目了然的
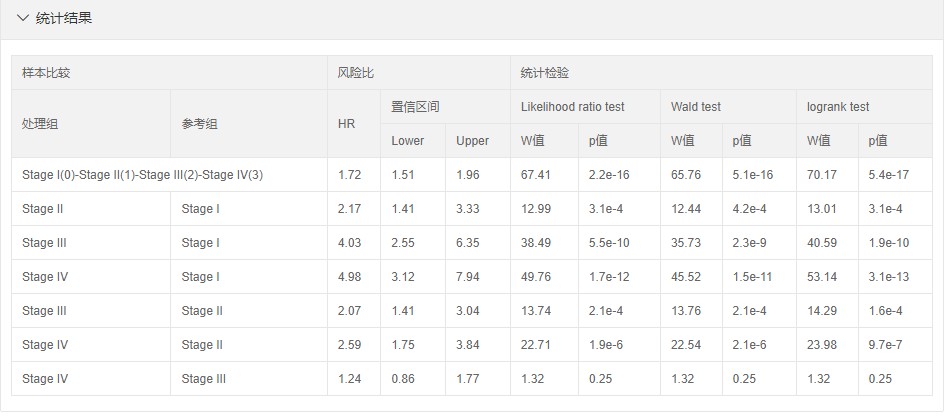
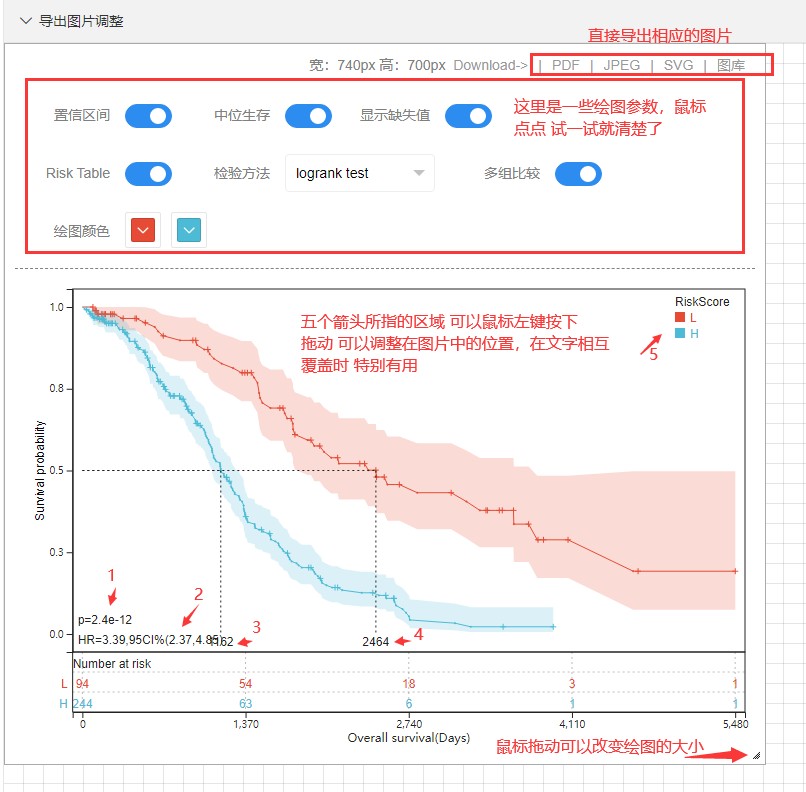 当然伴随着所有的统计结果如下,可以看到不同比较组之间的预后差异,和风险比及置信区间
当然伴随着所有的统计结果如下,可以看到不同比较组之间的预后差异,和风险比及置信区间
几个简单例子:
1、根据最优截断值来绘图
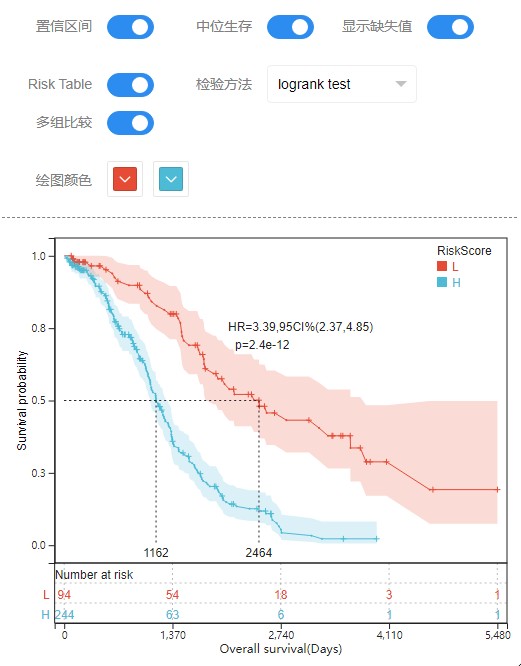 2、根据两分组来绘图
2、根据两分组来绘图
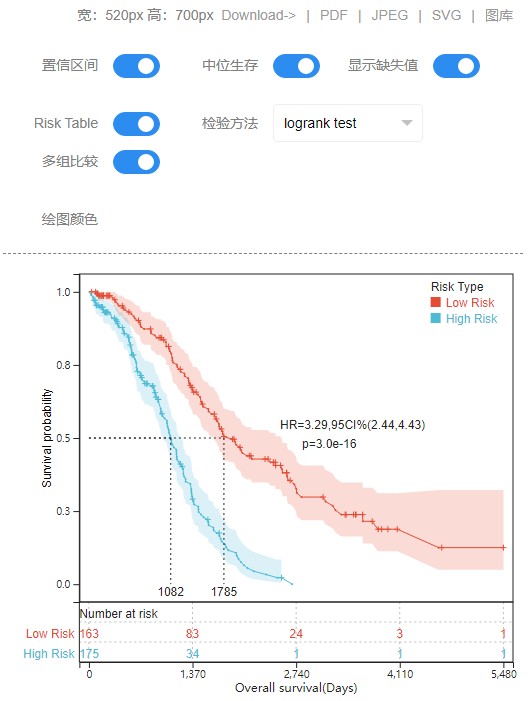
3、根据多个分组来绘图
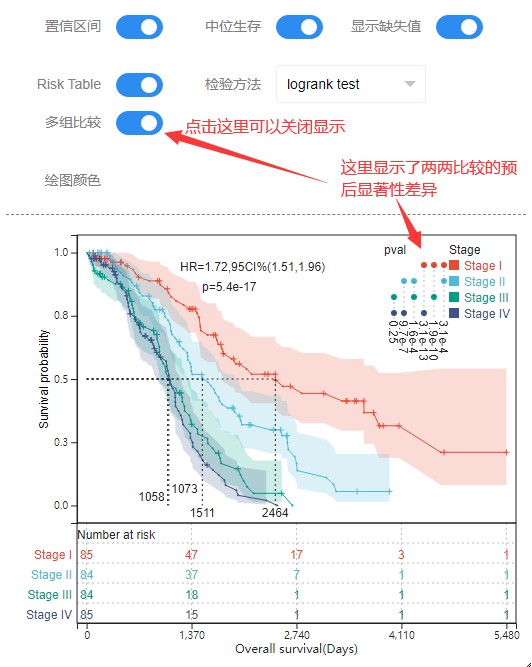 怎么看 生存分析结果,且看 知乎前辈的解读:
怎么看 生存分析结果,且看 知乎前辈的解读:
###########https://zhuanlan.zhihu.com/p/37088421#################
1,为什么要绘制生存曲线
可能有读者要问,为什么要绘制生存曲线?如果想要比较两组患者的预后,我直接比较两组的生存时间不就可以了。比如,我要比较早期肺癌和晚期肺癌的总体生存率,我可以将所有的病人随访到死,这个每个病人就有一个生存时间,我直接用t检验或者Mann-Whirney U检验等直接比较生存时间就行了,还绘制什么生存曲线。
然而,事情并不是那么简单!预后分析往往要考虑很多因素,比如病人失访了(失去联系),最终无法明确病人是否死亡。也有可能病人并不是死于预定的观察终点,比如研究肺癌预后,设定的观察终点是肺癌相关死亡事件,但问题在于有的病人中途可能死于车祸或心血管疾病,这类病人自然就没有观察终点了。在随访中,这些没有观察终点的案例叫失访案例,或者删失案例。当然,还有一个最重要的问题,就是有的疾病生存时间较长,比如睾丸癌,随访二三十年也未必能等到病人全部死亡。在这些情况中,如果仅仅比较生存时间,显然是不可能,也不合理的。打个极端的比方:某人对10例晚期和10例早期肺癌进行了1年的随访,旨在确定早期病人的预后是否好于晚期病人。作者对病人进行随访后发现,晚期病人在1年的时间截点上(刚好在1年的时候)全死了,而早期病人在1年的时间截点上还全部存活。如果单纯比较生存时间,早期和晚期病人的存活时间都是1年,显然没有差异。但是在这里例子中,早期病人的预后显然是优于晚期病人的。
也有人说,我不比较生存时间,而是比较1年生存率,5年生存率,这又何尝不可。这确实是一种预后分析的方法,但是其在方法学上有瑕疵,并不是最佳的预后分析方案。再打一个极端的比方,某研究者对甲乙两组肺癌病人进行随访,比较两组患者的1年生存率。随访1年后,两组病人均死亡,死亡率是100%,如果单独比较1年生存率,两组患者的死亡率显然是一样的。但是问题在于:甲组病人全部是在随访后3天就死了,而乙组病人全部是在第364天死亡的。其实乙组病人比甲组病人多活了近一年,其预后显然更好。这个案例其实就是告诉我们,生存分析要考虑每个时间点上病人的生存概率,而不是某一个特定的时间点。
其实说了这么多废话,举了这么多例子,就是想说明一个问题:随访资料是有删失值的,比较病人的预后不能直接拿随访时间说事,生存曲线才是最佳分析方案。
2,如何解读生存曲线

图1
上图(图1)是笔者随手从某杂志上截取的一张生存曲线图。这项研究的目的之一评价sST2(一个实验室指标)与呼吸困难人群预后,作者选择观察终点为全因死亡率。研究将251例呼吸困难人群划分为两个组,sST2增高组(n=126)和降低组(n=125)。用生存曲线描述了两组病人的生存状况。生存曲线的横坐标是观察时间,纵坐标一般是生存率。曲线上的每一个点代表了在该时间点上病人的生存率。在A点中,由于才开始随访(X轴为0),还没有患者死亡,所以两组患者的生存率都是100%。但是我们发现,在随后的随访过程中,sST2增高组(sST2>median)的死亡率在任何一个时间均高于sST2降低组(sST2=<median)。以第200天为例,sST2降低组的生存率约为93%(B点),而增高组的生存率则为70%左右(C点)。从这个数据中,我们大致可以判断sST2降低组的全因死亡风险要低于增高组。但是这仅仅是推测,无法排除两组患者全因死亡风险的差异是由于随机抽样造成的。要证明这个推测,需要在统计学上进行假设检验。目前对生存曲线的假设检验一般采用logrank检验,该检验在常用的统计软件中均可实现,具体的操作过程我会另辟新文进行演示,敬请关注。Logrank检验的统计学原理比较复杂,对临床研究工作者来说,不必完全掌握,只需要了解该检验的统计学结论和临床解释即可。经logrank检验后发现P<0.05,表明两组患者的生存状况(准确地说是观察终点的发生状况)的差异不能用抽样误差来解释。换而言之,分组因素才是导致两条曲线生存率出现差异的原因所在。以上图为例,经过logrank检验后发现P<0.05,作者可以理直气壮地告诉读者:sST2降低组和增高组的总体生存率是完全不同的,sST2降低组的总体生存率要好于sST2增高组。
当然,生存曲线也可以是3组,4组甚至多组,在图形绘制和统计分析的操作上与两组分析如出一辙,在此不再赘述。下面是笔者对生存曲线一些特性的认识,便于大家认识和理解生存曲线。内容虽然简短,但是均为“干货”。
2.1 样本量越大,生存曲线越平滑,误差越小。下图(图2)是我从另一篇文章中截取的总体样本量为99的研究,其曲线的平滑程度显然比不上前述样本量为251的研究。
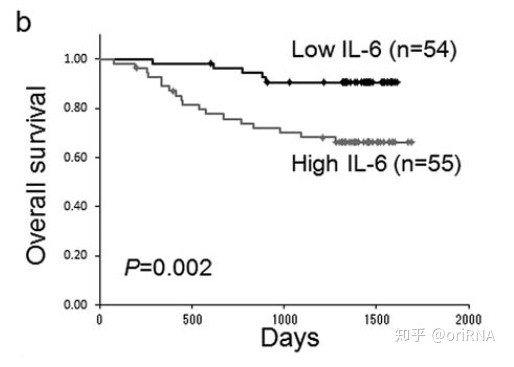
图2
2.2 一般而言,两条曲线之间的距离越大(分叉越大),说明两组患者预后(终点事件发生率)的差别越大,也越容易做出统计学差异。其实这个和t检验差不多:两组数据的均数差异越大,越容易有统计学差异。
2.3 随访时间越长,越容易做出统计学差异。这个问题其实也很好理解,一个极端的比方就是,在上述sST2例子中,假定随访时间为1天,而非400天,两组患者生存率的差异显然是没有统计学意义的。国际上,随访时间越长的研究越容易发表在高水平的杂志上,原因与此有关。
2.4 样本量越大,越容易做出统计学差异。样本量越大,误差(标准误)越小,当然越有统计学意义。其实这相当于在t检验中,两组数据的标准差越小,当然越容易得到阳性统计学结果。
2.5 生存曲线与X轴有交叉,并不意味着研究对象全部死亡(发生终点事件)。实际上,在生存曲线中,每一个时间点上只要有病人死亡(或者发生终点事件),曲线就会下降一定的幅度。下降的幅度具体有多大,取决于该时间点上病人的死亡例数和后续随访时间(该时间截点以后的时间)病人的样本量。这句话可能有些晦涩和难于理解,举一个通俗的例子:某研究者随访了10例病人,随访第一天就有两个病人去世了,第一天的生存率就是80%,即曲线下降了20%的幅度。到随访第二天,4个病人失访了。由于只是失访,而不是死亡,所以生存曲线不会下降,而是继续水平延生。到第三天的时候,还有随访资料的病人仅有4个。而恰好就在这一天,两个病人去世了,曲线下降的幅度就应该是剩余幅度的50%(四个病人中的两个)。由于第二天仅仅只有4人失访,而不是死亡,所以生存曲线在第二天的生存率仍然是80%。到第三天时候,曲线的下降幅度就应该是80%的50%,即下降40%。假定第四天的时候,剩下的两个病人都死了,所有研究对象在第四天的生存率自然是0%。实际上,这些病人的生存曲线图就是如下图(图3)所示:
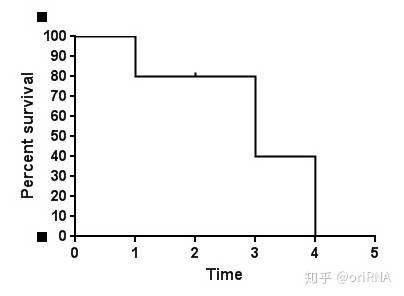
图3
从图中(图3)我们可以看出:1)这个生存曲线图太不平滑了,主要是样本量太小;2)生存曲线虽然与X轴相交,但是并不是所有的研究对象都死亡了,因为其中有4人属于失访病例,即删失结果。我们经常看到很多生存曲线与X轴并无交点,实际上就是经过长时间的随访后,仍有大量病人存活,无法明确这些病人具体的死亡时间(删失结果)。在上图中,我们假定第四天的时候,剩下的两个病人还是存活的,但是研究也结束了(不再对病人进行随访),则其对应的生存曲线图应该为下图(图4):
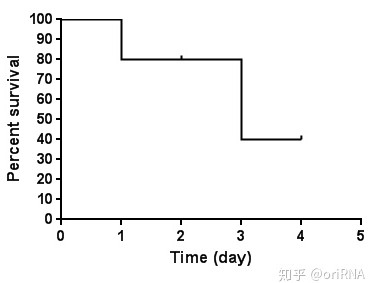
图4
因此,生存曲线是否与X轴有交叉,主要取决于随访时间最长的那位患者是生存还是死亡,若为死亡,则自然与X轴相交。
2.6 理想的生存曲线应该标明删失值。在上述例子中,我们注意到,生存曲线第二天和第四天上面有一个突出的小点,表示表示该点有删失病例。实际上,这才是最正规、最具有信息量的生存曲线。遗憾的是,目前刊登在很多杂志,包括部分国际杂志上的生存曲线都不按照这个规则绘制,作者总是有意无意地抹去删失病例的“凸点”。
2.7 在生存曲线的下方,最好能标识下每组的样本量,分组的依据(比如sST2的平均值)等,因为这些细节可以方便循证医学家对论文的数据进行提取和合并,这些细节有助于增强自己论文的学术穿透力。
笔者| 胡志德,Journal of Thoracic Disease学术沙龙委员、Section Editor (Systematic Review and Meta-analysis),工作于济南军区总医院实验诊断科,现为第二军医大学临床检验诊断学博士研究生,以第一作者或通讯作者身份发表SCI论文十余篇,并主持国家青年科学基金一项。
- 发表于 2021-06-24 10:22
- 阅读 ( 11239 )
- 分类:软件工具
