GEO和TCGA数据库挖掘文章思路!
文章,重在研究思路;有好的思路,才能有精彩的故事。很多时候,我们想找一个好点子,比如性状,疾病相关的关键分子,需要设计实验,做大量的分子筛选的工作。对于土豪实验室可以大把的花钱做芯片或者高通量测序做前期的筛选工作。但是毕竟土豪是少数的,假如您样本不多,经费较少,而又想发SCI文章,该怎么办呢?下面我给大家推荐一个最经济最快捷最有效的文章思路:利用别人已发表的数据,筛选出一些有价值的分子(mRNA,miRNA,lncRNA,circRNA,lncRNA),之后在自己的小样本中验证一下,发篇SCI文章还是轻轻松松的。下面我们一起来看看这类利用GEO、TCGA数据库的文章是怎样写成的!
文章1:

文章今年(2018)发表在:Cancer Management and Research 上IF=3.851。该文章发表的杂志影响因子虽然不高,但是分析思路还是可以借鉴的:文章主要分析结论是:利用公共数据(GEO,TCGA数据),通过数据筛选分析后发现两个miRNA(miR-182 and miR-20a)可以作为结直肠癌(colorectal cancer CRC)诊断的分子标志物,然后在组织和血液中进行验证,最终确定诊断参数。主要的分析思路分为三大步,如下图所示图所示:
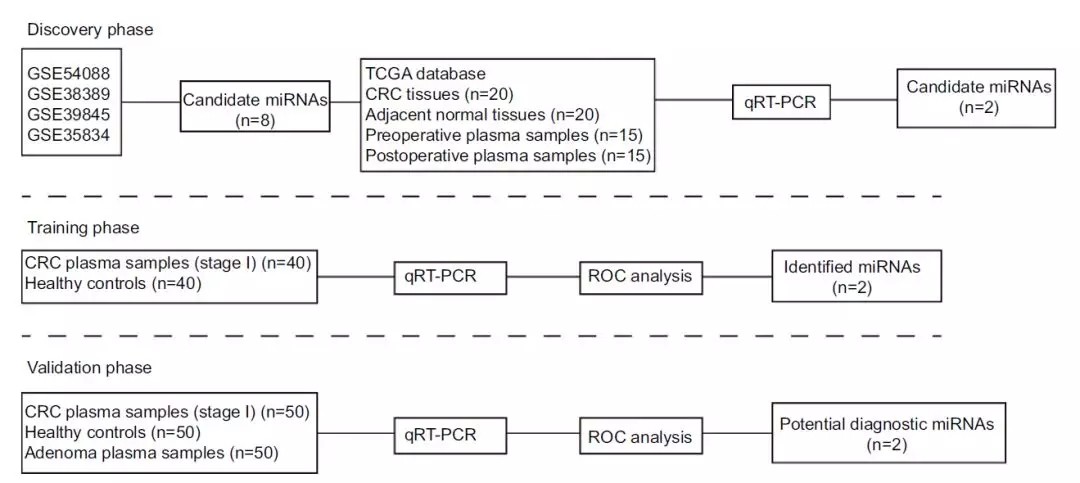 第一步:利用公共数据进行筛选biomarker(Discovery phase)
第一步:利用公共数据进行筛选biomarker(Discovery phase)
首先,作者利用GEO数据库当中关于CRC的4个miRNA表达芯片数据,寻找患病样品和正常样品中差异表达的miRNA,通过取交集初步筛选到8个miRNA,再利用TCGA数据库中的CRC样本进行筛选,和qRT-PCR验证,其验证不仅在组织样中,同时还在血液中进行筛选,方便后续通过血液检测筛查CRC患者。最终确定了两个miRNA在CRC患者的组织和血液中表达都有上调,可作为CRC的分子诊断候选标志物(miR-182 and miR-20a)。
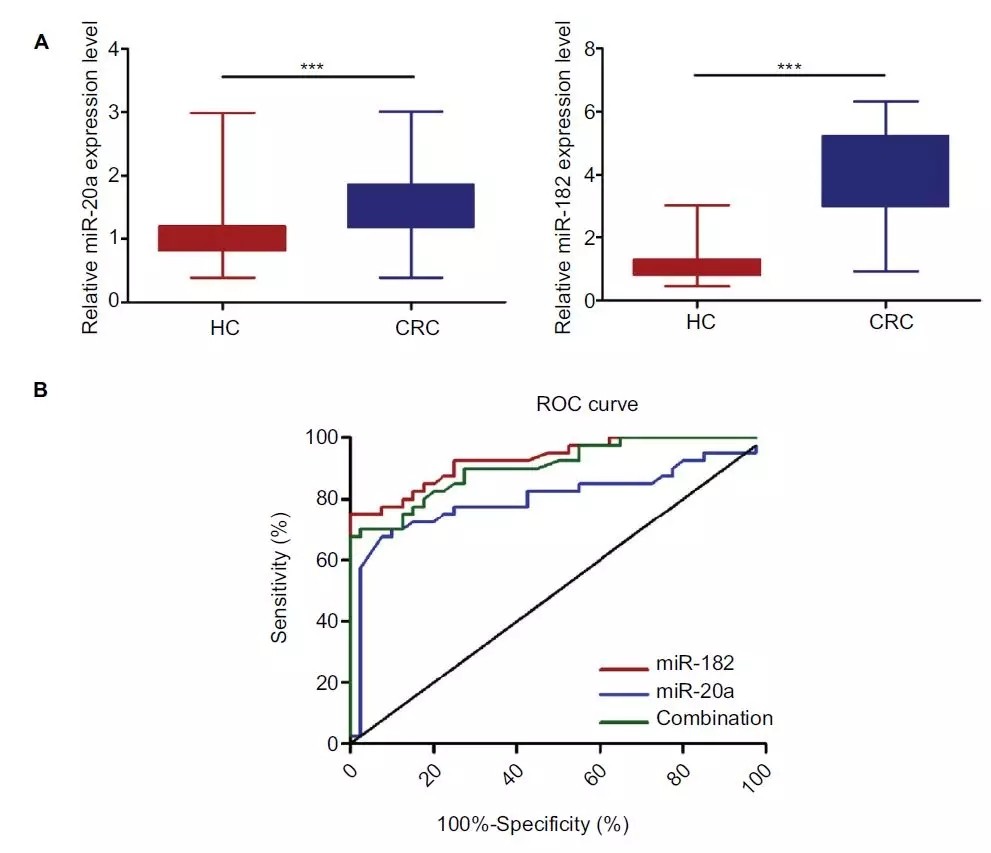
 第二步:做训练数据集,确定诊断参数(Training phase)
第二步:做训练数据集,确定诊断参数(Training phase)
之后,作者在自己收集的CRC患者血液样本中进行验证,40个健康样品,40个CRC患者样本,发现这两个miRNA在患者和对照中表达都存在差异,最终通过分析ROC线确定分类参数。
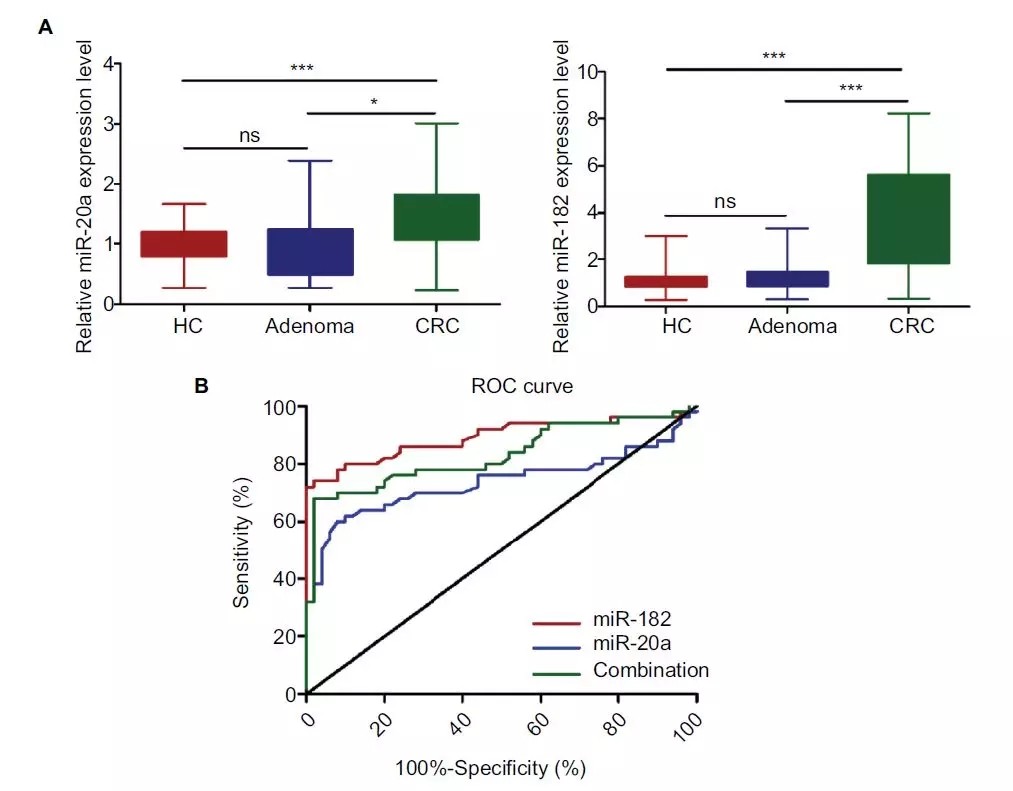
 第三步:扩大数据集,确定最佳诊断参数(Validation phase)
第三步:扩大数据集,确定最佳诊断参数(Validation phase)
最后作者扩大样品到150个,分别为健康样品50个,Adenoma(腺瘤)样品50个和CRC患者(stage I)进行验证并绘制ROC曲线,最终确定,诊断参数:
miR-182,miR-20a, and 2-miRNA combination were 2.620, 1.355,and 2.147, respectively.
文章2:
题目:Expression profiles analysis identifies anovel three-mRNA signature to predict overall survival in oral squamous cellcarcinoma
期刊:Am J Cancer Res
分数:3.2
疾病:口腔鳞细胞癌(OSCC)
文章思路:
利用GSE13601,GSE30784, GSE37991三个mRNA芯片表达数据以及TCGA中OSCC表达数据分别做对照和患者差异基因分析,筛选到显著差异表达的76个上调基因、106个下调基因;然后进行GO和KEGG通路富集分析、PPI网络分析,IPA通路分析,生存分析等联合分析最终筛选到PLAU, CLDN8 and CDKN2A与OSCC预后相关,并且在另一个GEO数据GSE41613中得到了验证。
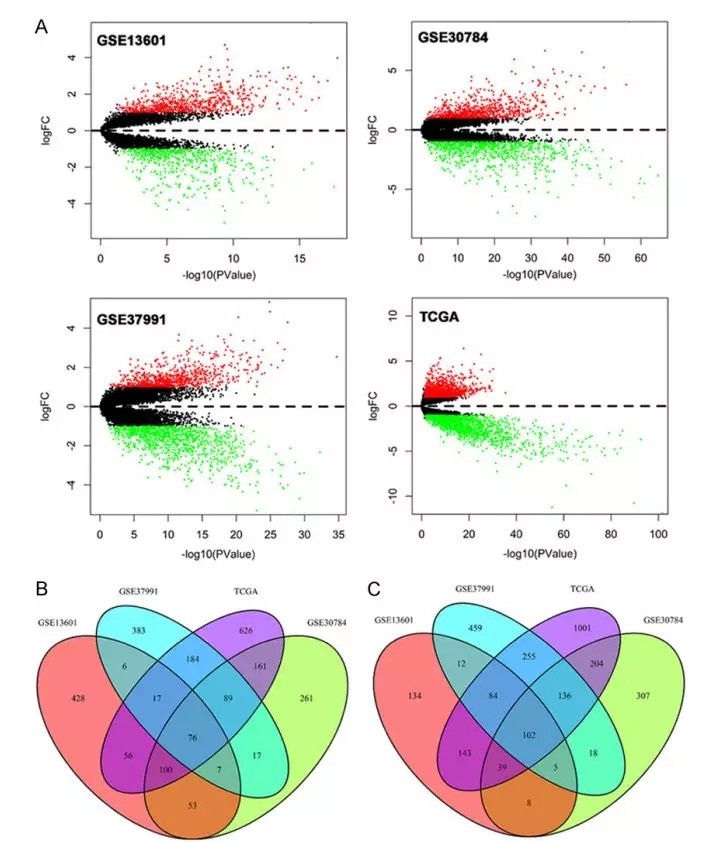
总结:
大家可以发现,GEO数据挖掘,以及TCGA数据的挖掘就是这个套路(点击观看),先确定自己要分析的疾病,然后下载数据,差异表达分析,筛选得到几个关键的分子(可以是lncRNA,mRNA,miRNA,circRNA),然后进行GO富集分析、Pathway富集分析、GSEA富集分析、PPI分析、IPA通路分析等,最后再做生存分析、ROC曲线分析等,就可以得到与疾病诊断相关的biomarker。如果要进一步发高分的文章,可以再做一下小鼠模型,细胞模型,敲除,过表达等补充实验,对分子机理进行深入研究,干湿结合,文章就能再上一个档次。另外,还有其他套路组合,例如做一下WGCNA或者联合Oncomine数据挖掘等等。
- 发表于 2018-07-19 08:48
- 阅读 ( 32336 )
- 分类:转录组学
