生信分析云平台产品开发 - 4 生信分析pipeline图形化
前文链接:
生信分析云平台产品开发 - 3 生信分析pipeline的进化
在上文 生信分析云平台产品开发 - 3 生信分析pipeline的进化 讨论了生信分析pipeline的进化,
从手动到自动,但仍然停留在终端命令行阶段,为了让更多非生信专业的人能够使用,就要想办法实现
生信分析pipeline的图形化:提供能够快速上手的UI,简单点击鼠标就能够运行的图形化系统。
核心功能:pipeline的图形化工作流设计器变量处理:要实现pipeline图形设计器,首先要先对用到的变量,做统一的设计。
变量的分类: 根据实际经验,pipeline变量用到根据用途可以分为以下几类:
分析数据目录${data} 分析过程输出目录${result}
分析用到的软件 bwa ${tools.bwa};samtools ${tools.samtools}
分析流程中用的reference文件以及数据库,如 hg19.fa ${ref.hg19}
分析流程中,用到的cutoff值. 如 cnv的cutoff值 ${cutoff.cnv}
分析流程运行时配置的资源,如 线程数 ${threads} 分配内存大小${mem}
变量值的类型:
字符:通用的格式,比较宽松
程序:校验变量值时,判断文件是否存在,是否有可执行权限
文件:校验变量值时,判断文件是否存在,是否有读写权限
目录:校验变量时,判断目录是否存在,是否有读写权限
数值:校验变量时,判断是否为数值格式
最终设计数据好数据结构,做好增删改查功能,UI如下:
分析步骤/节点设计:前文提到,生信分析pipeline其实就是基于文件输入输出的工作流,这里对工作流做了简化,归纳起来工作流中有4种节点。
Input节点,提供pipeline的起始输入文件
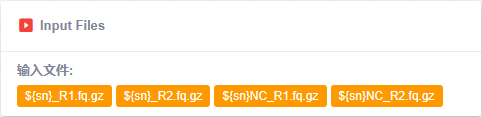
Output节点,获取pipeline的最终输出文件

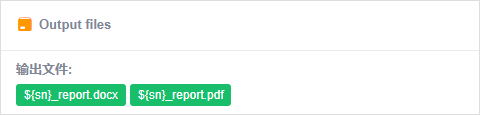
Task节点,输入文件,运行分析过程,输出分析过程运行结果

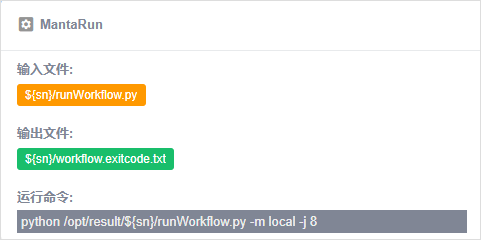
Database节点,部分pipeline运行结果,需要将输出文件保存至系统数据库中
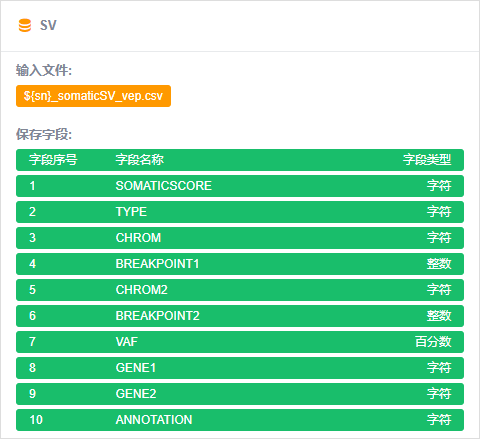
工作流设计: 最后,有了变量,和节点,最后就是工作流的设计了。用连接线,将以上4中节点连接起来,计算相互之间的依赖关系,用统一的格式保存起来。
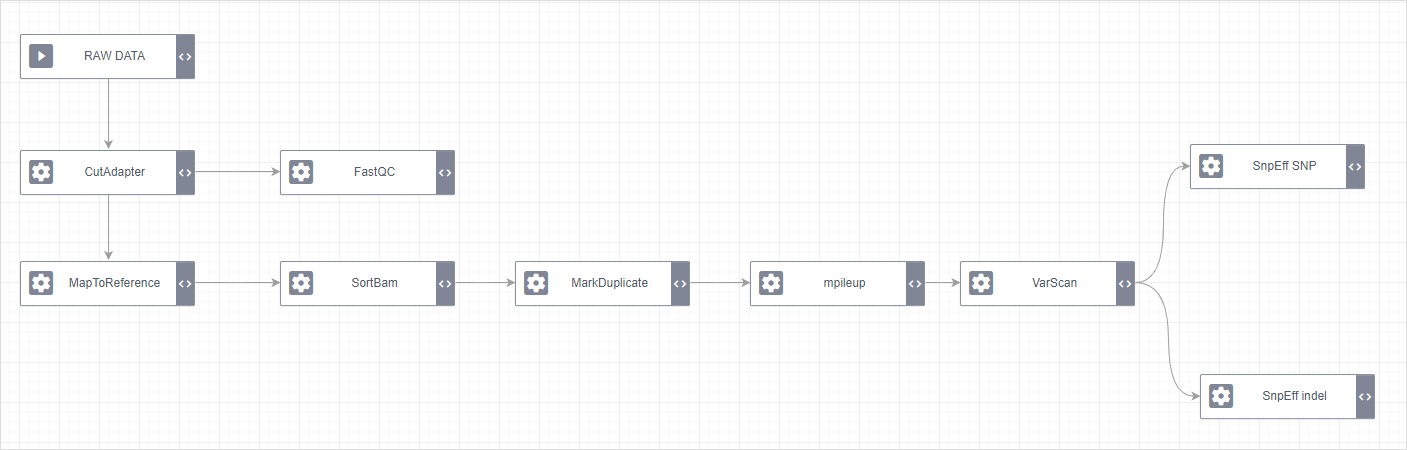
设计器功能增强:
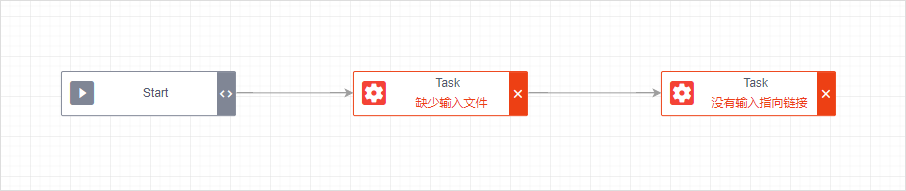
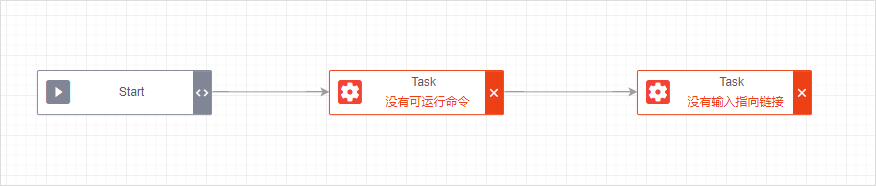
当分析节点没有相互连接时候,要提示错误

修正Start的错误后,重新验证状态时:
在Task任务中选择Start输入的文件,并填写好输出文件后:保存时提示,没有运行的命令:
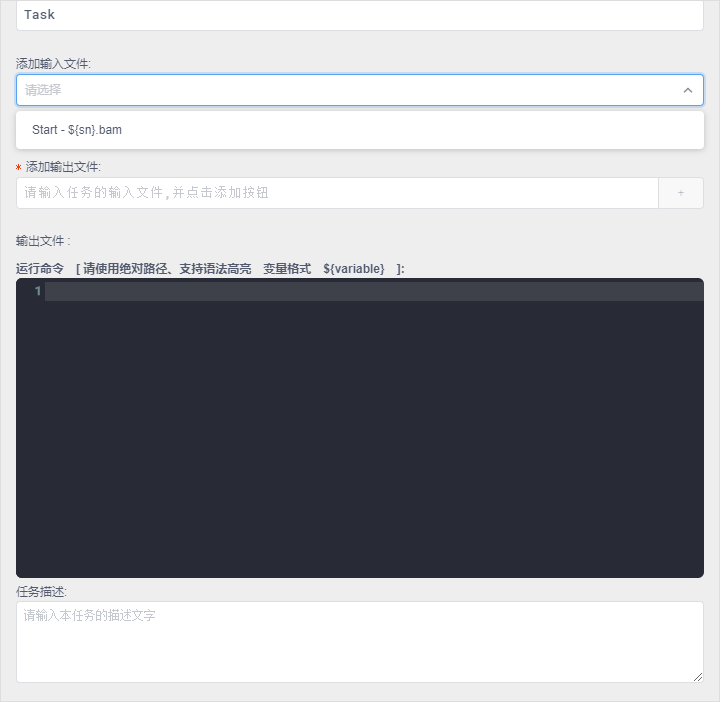
在Task中输入运行的命令,可以看到:变量提供了语法着色显示,防止输错
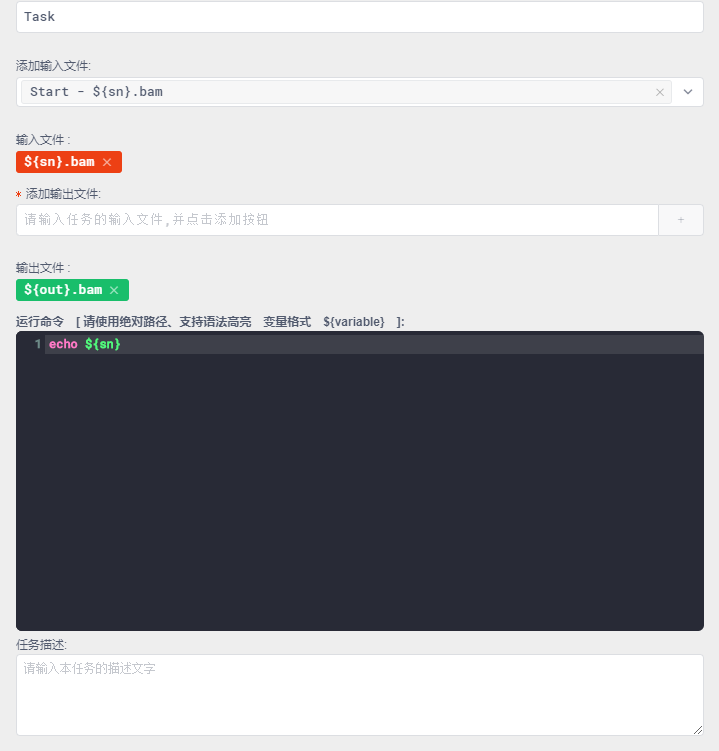
最终满足校验要求后,工作流是这样的:

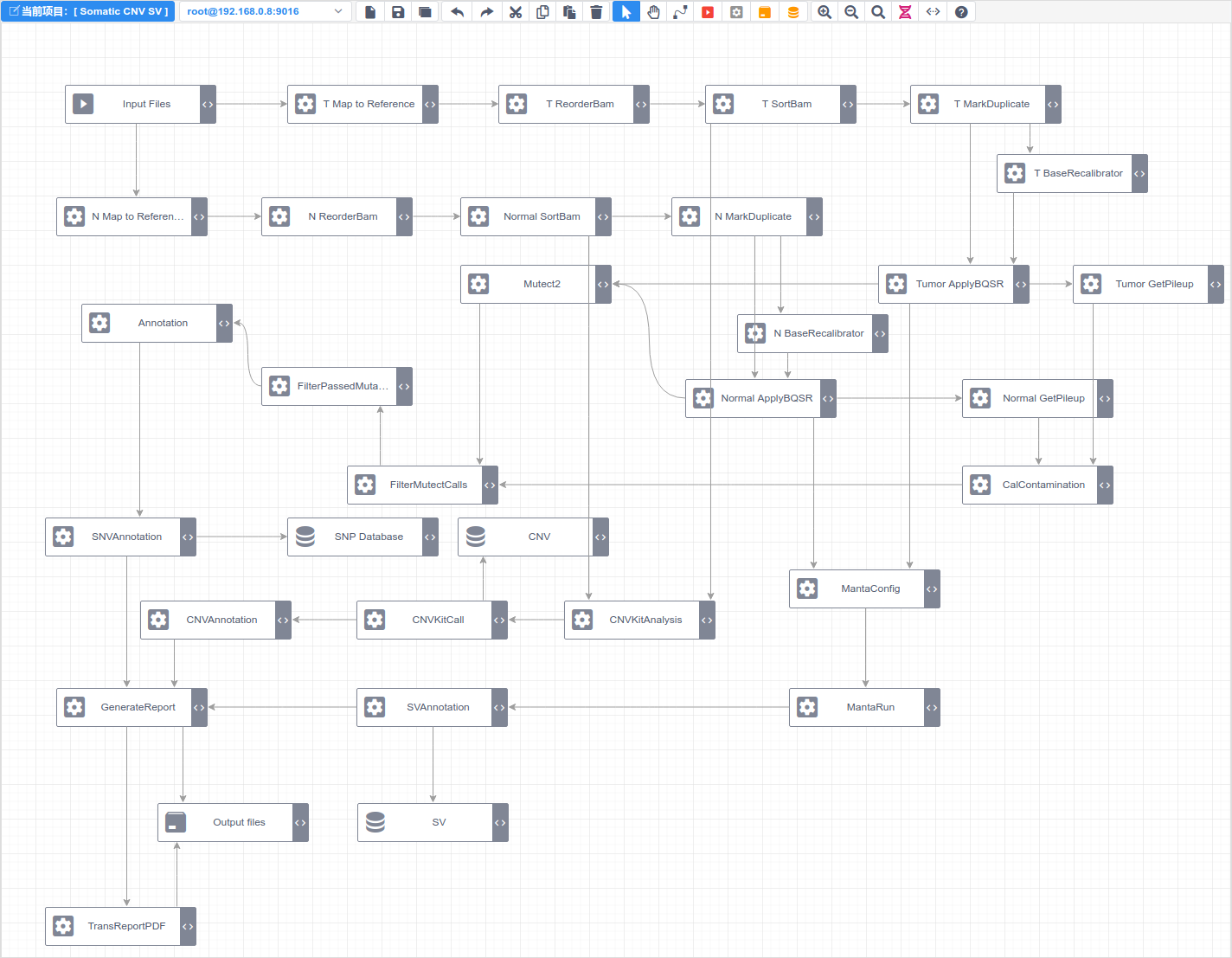
最后上一张,完成了的工作流设计器:
欢迎回复讨论或者加入QQ群:853718264
- 发表于 2019-09-19 13:23
- 阅读 ( 5215 )
- 分类:软件工具
