生信分析云平台产品开发 - 6 生信分析pipeline批量运行与过程控制
前文链接:
生信分析云平台产品开发 - 3 生信分析pipeline的进化
生信分析云平台产品开发 - 4 生信分析pipeline的图形化
生信分析云平台产品开发 - 5 生信分析pipeline服务器端运行
在上文生信分析云平台产品开发 - 5 生信分析pipeline服务器端运行 解决了设计好的流程在分析服务器上运行的问题,随之而来就衍生出的新需求:
一、分析流程的批量运行顺序
流程输入文件是按照样本编号来匹配运行的,运行顺序就取决于样本信息
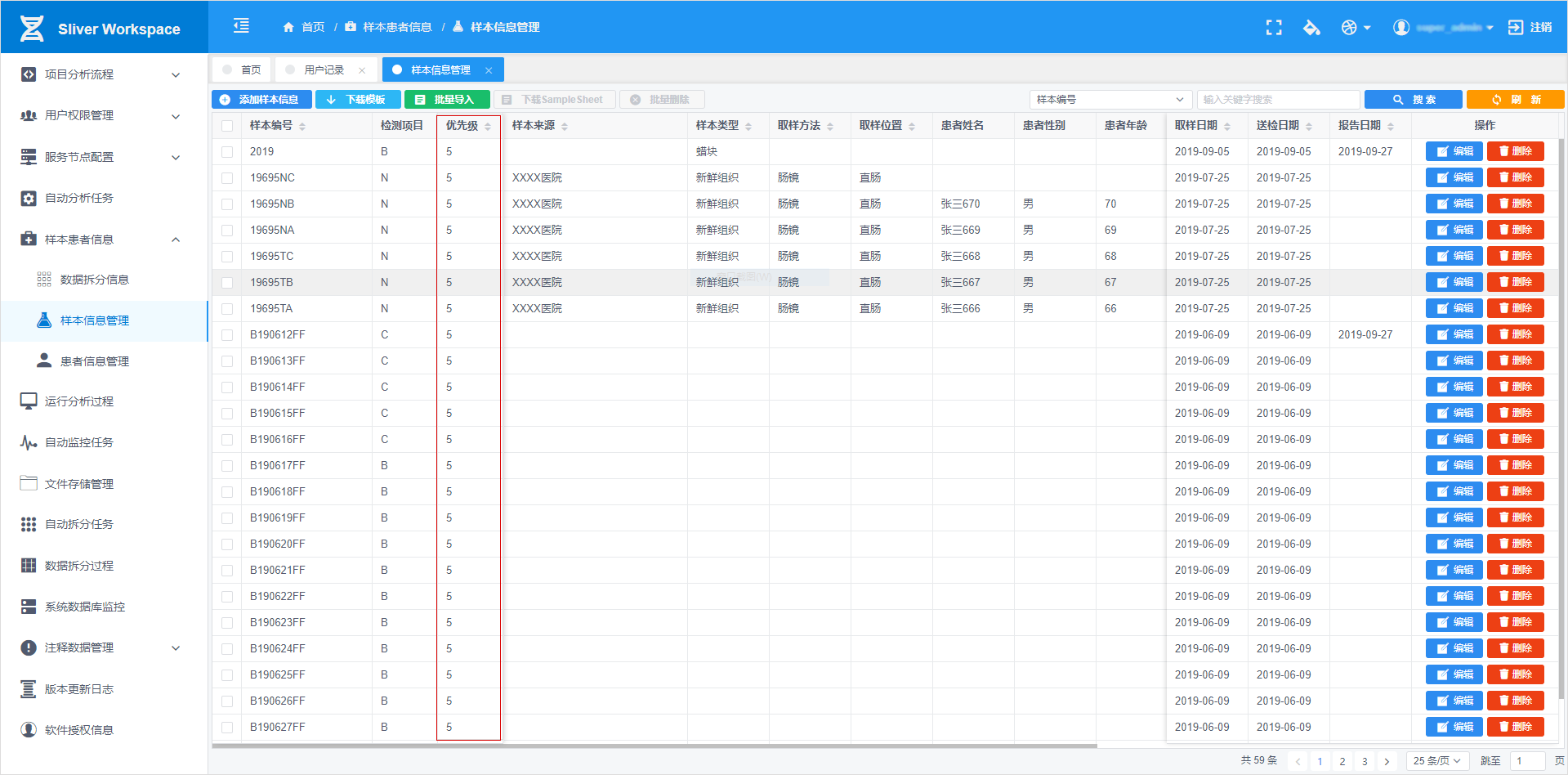
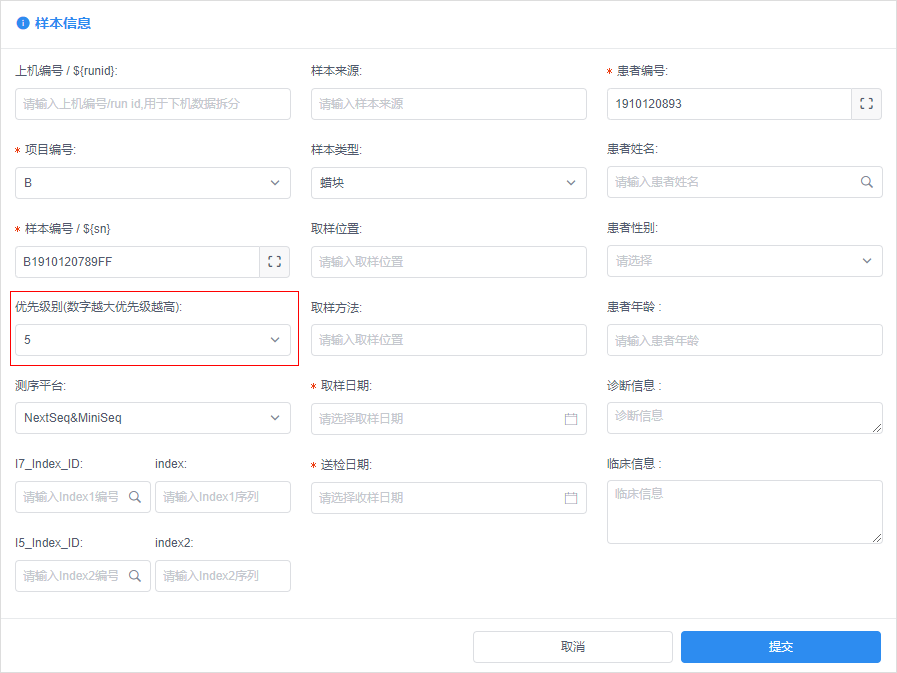
样本优先级:此处设计样本录入时候,输入优先级字段范围1-9,数字越大优先级越高
样本顺序:样本默认按照录入的时间先后排序,相同优先级的样本数据,按照录入先后顺序排序运行
二、分析流程的过程控制
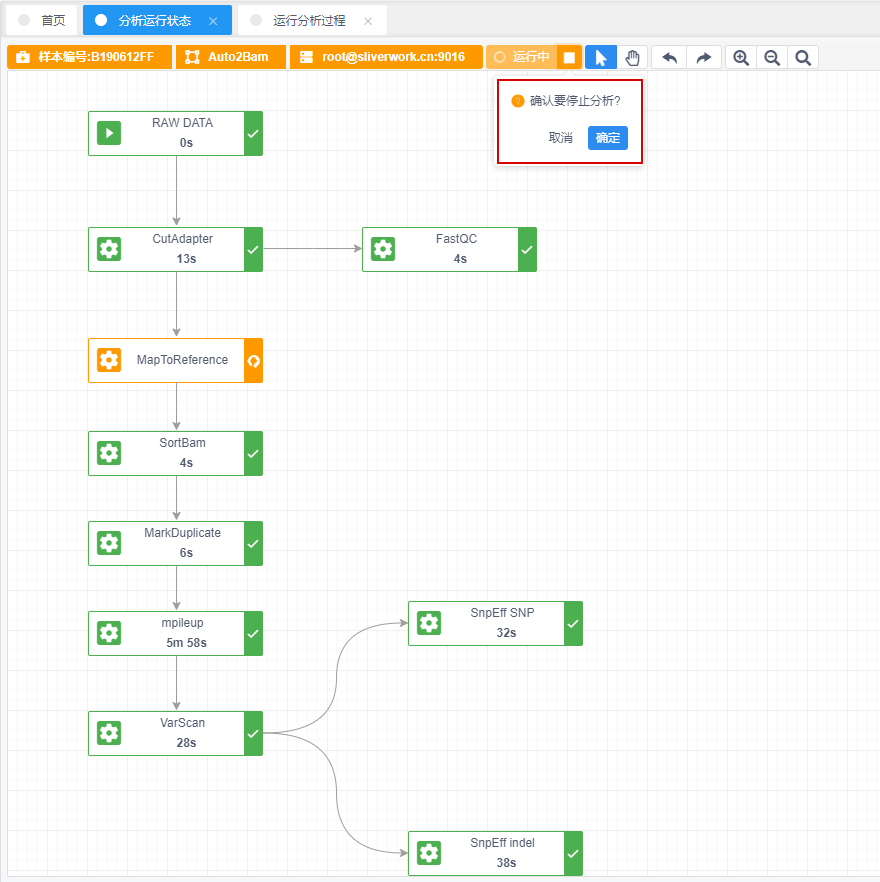
强制停止:开始分析流程之后,可以在任意时间停止分析过程
错误恢复运行:分析流程运行错误,再次运行,可以选择从错误处恢复运行
调试恢复运行:分析结束,修改pipeline参数后,可以选择从任意一点开始重新分析(应用修改后的参数)
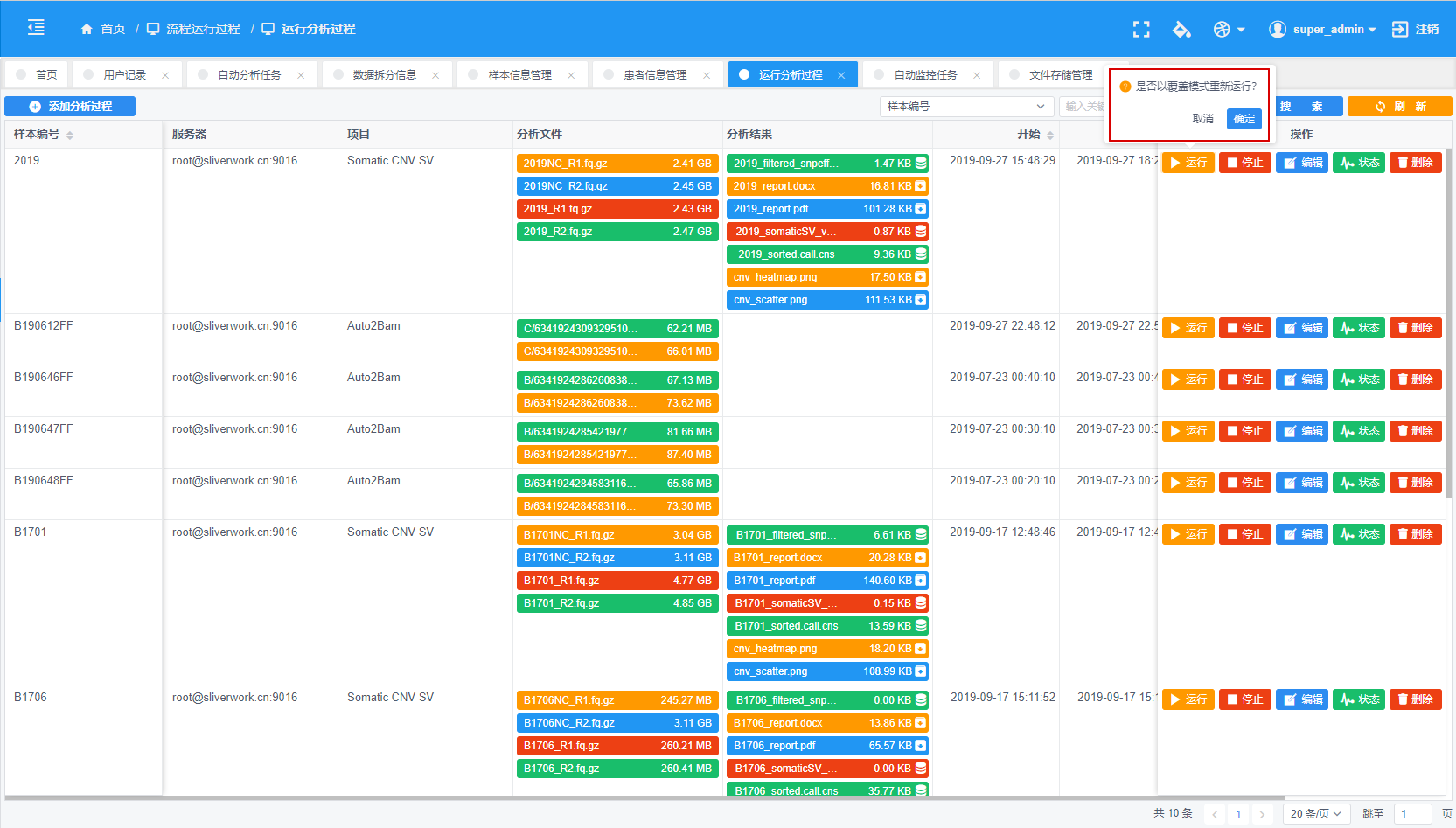
覆盖运行:分析错误或者正常结束后,重新从头开始运行整个分析流程,并覆盖之前的分析结果
技术实现:
一、批量样本分析流程的运行顺序:
依赖于样本的优先级和输入的顺序先后,每次从数据库取出未完成分析的样本列表,按照优先级从高到低,样本输入先后顺序排序。
每次列表中取最上面一个,去指定目录里匹配输入文件,如果输入文件符合匹配要求,立即启动pipeline,开始流程分析。同时更新该样本状态为正在分析,这样下次排序时候就不会重复获取该样本了。
其实就是一个带有优先级参数的先进先出的堆栈
二、分析流程的控制
前文描述了如何将设计好的pipeline运行于服务器,如果要监控整个运行过程,就需要创建一个守护线程,如果用户操作停止分析,这时候守护进程就要终止运行进程,然后报错并返回。
同时,这个守护线程,要负有和前端通信,统计每个分析任务的运行时间,检查分析任务输出是否符合要求等等。
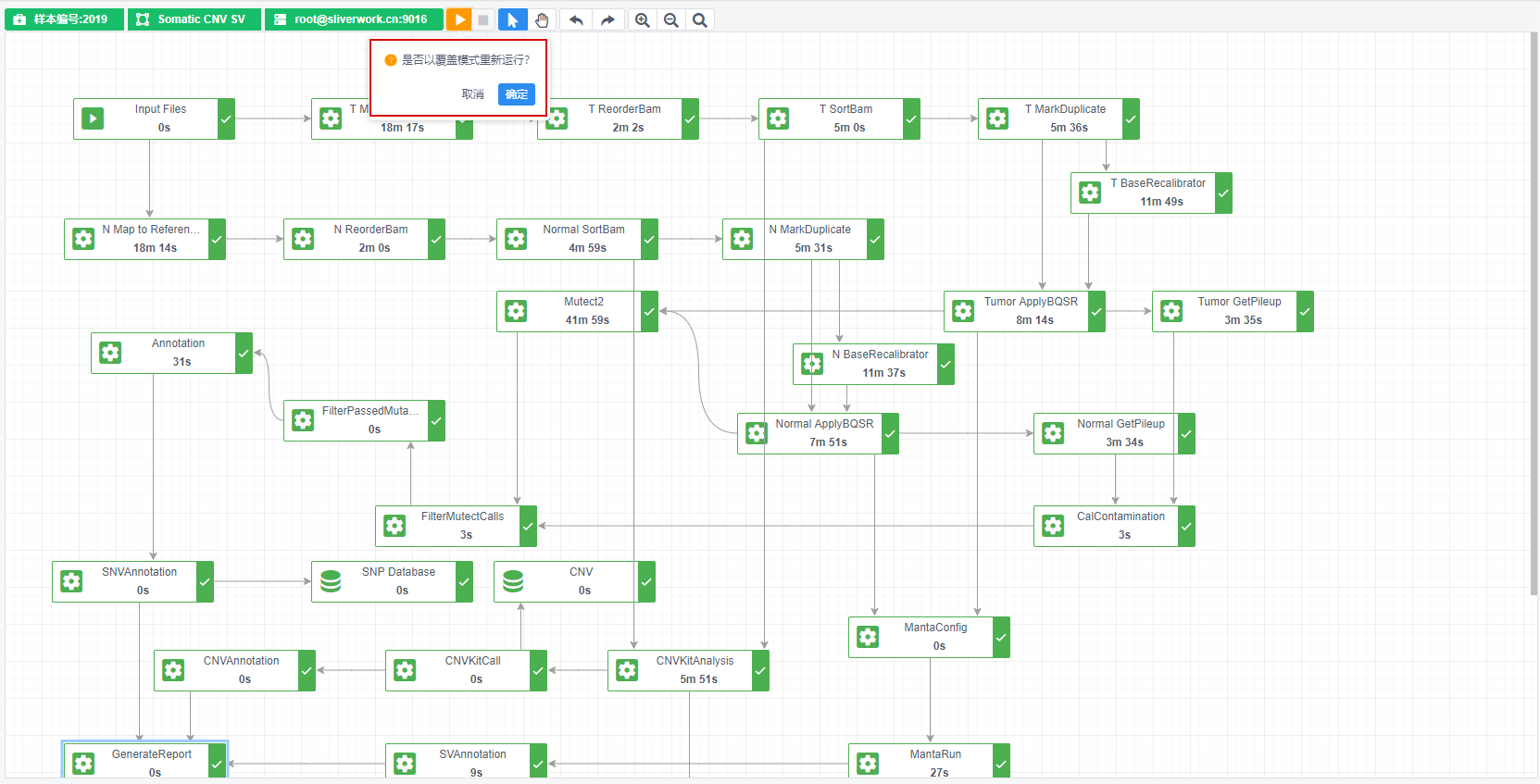
实现效果图:
样本优先级
强制停止
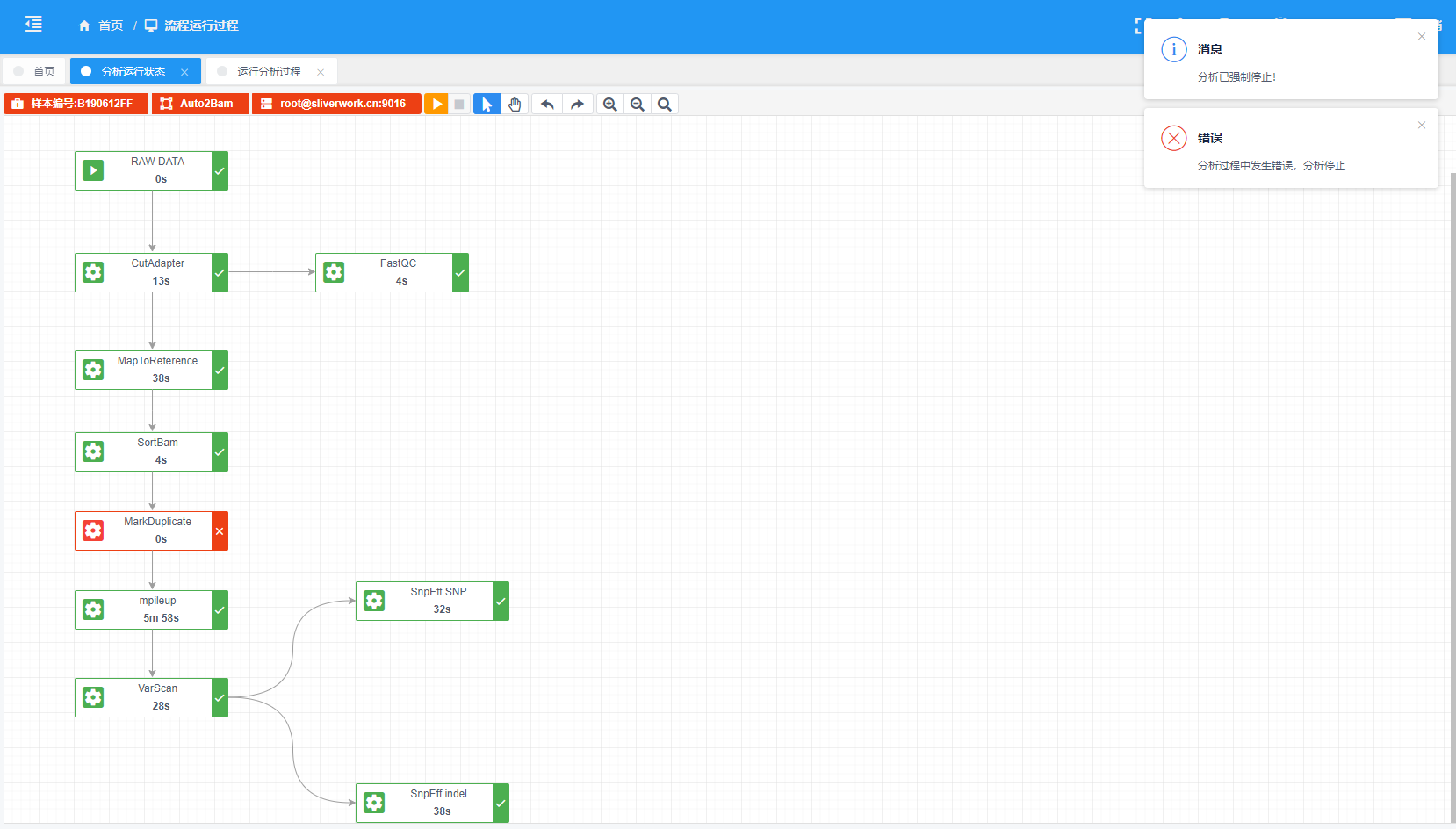
错误恢复运行
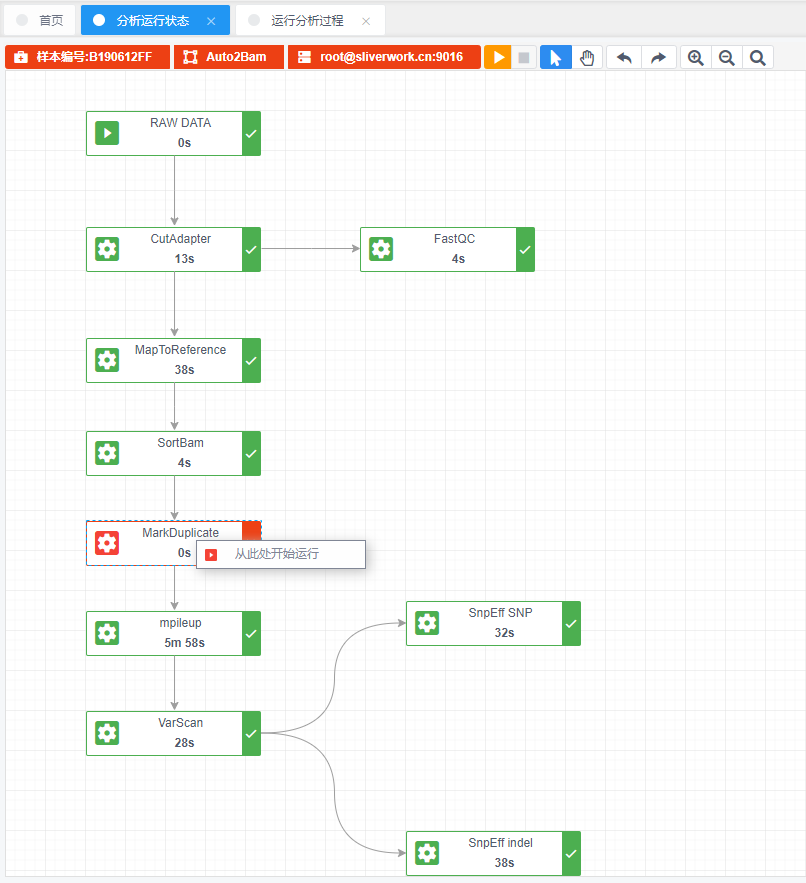
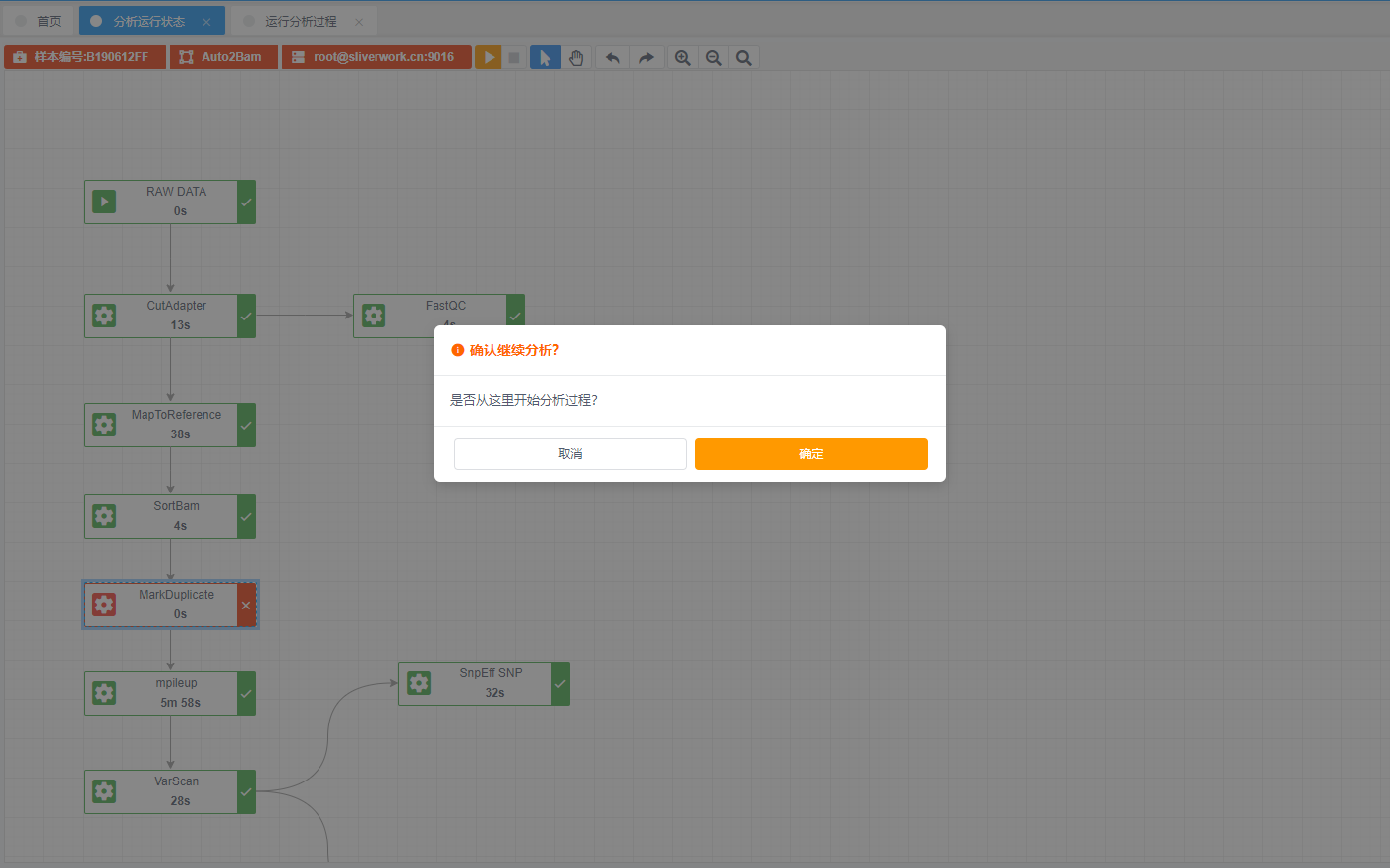
调试恢复运行
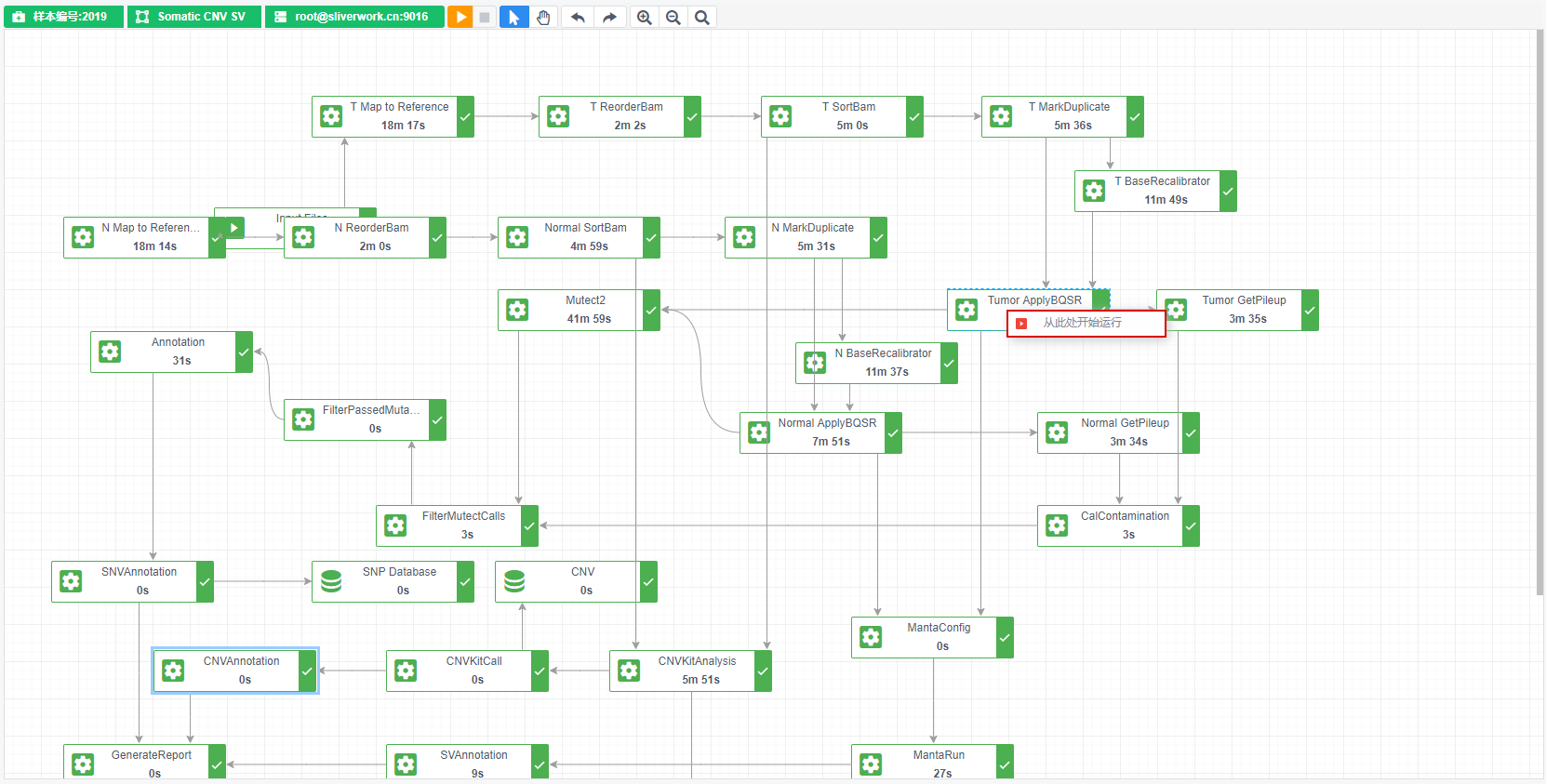
覆盖运行
欢迎回复讨论或者加入QQ群:853718264
- 发表于 2019-10-14 12:28
- 阅读 ( 3982 )
- 分类:软件工具
