生信分析云平台产品开发 - 5 生信分析pipeline服务器端运行
前文链接:
生信分析云平台产品开发 - 3 生信分析pipeline的进化
生信分析云平台产品开发 - 4 生信分析pipeline的图形化
在上文生信分析云平台产品开发 - 4 生信分析pipeline的图形化 讨论了生信分析pipeline的图形化,如何用图形的方式显示生信pipeline,但是pipeline脚本按照变量的形式保存之后,如何运行,在什么环境下运行?是本文要解决的问题。
运行方式:本地 VS 远程1. 本地模式:
优势:容易实现,运行效率高,不依赖网络
劣势:限制了软件的适用范围,本机性能就决定了分析性能,不易扩展,限于运算量较低的业务。
2. 远程模式:
优势:便于扩展,部署方便。本程序作为控制端,可以和分析端部署在一台机器,也可以通过联网方式连接。这样就可以把控制端单独部署,控制一个服务器集合>从单台到简单的集群
劣势:增加了编程复杂度;需要编程实现与服务器端的交互,并保持长连接,时刻保持通信。分析过程状态、服务器运行状态,需要由服务器端推送到用户端。
综合考虑,结合软件设计目标,这里选择远程模式
运行服务器节点:
服务器节点信息:
经常手动分析脚本的朋友大家的习惯可能是,ssh远程登录Linux服务器,在shell控制台输入各种脚本,软件。这里首先要解决的就是服务器信息的保存,操作。根据日常习惯归纳实现后,上图:
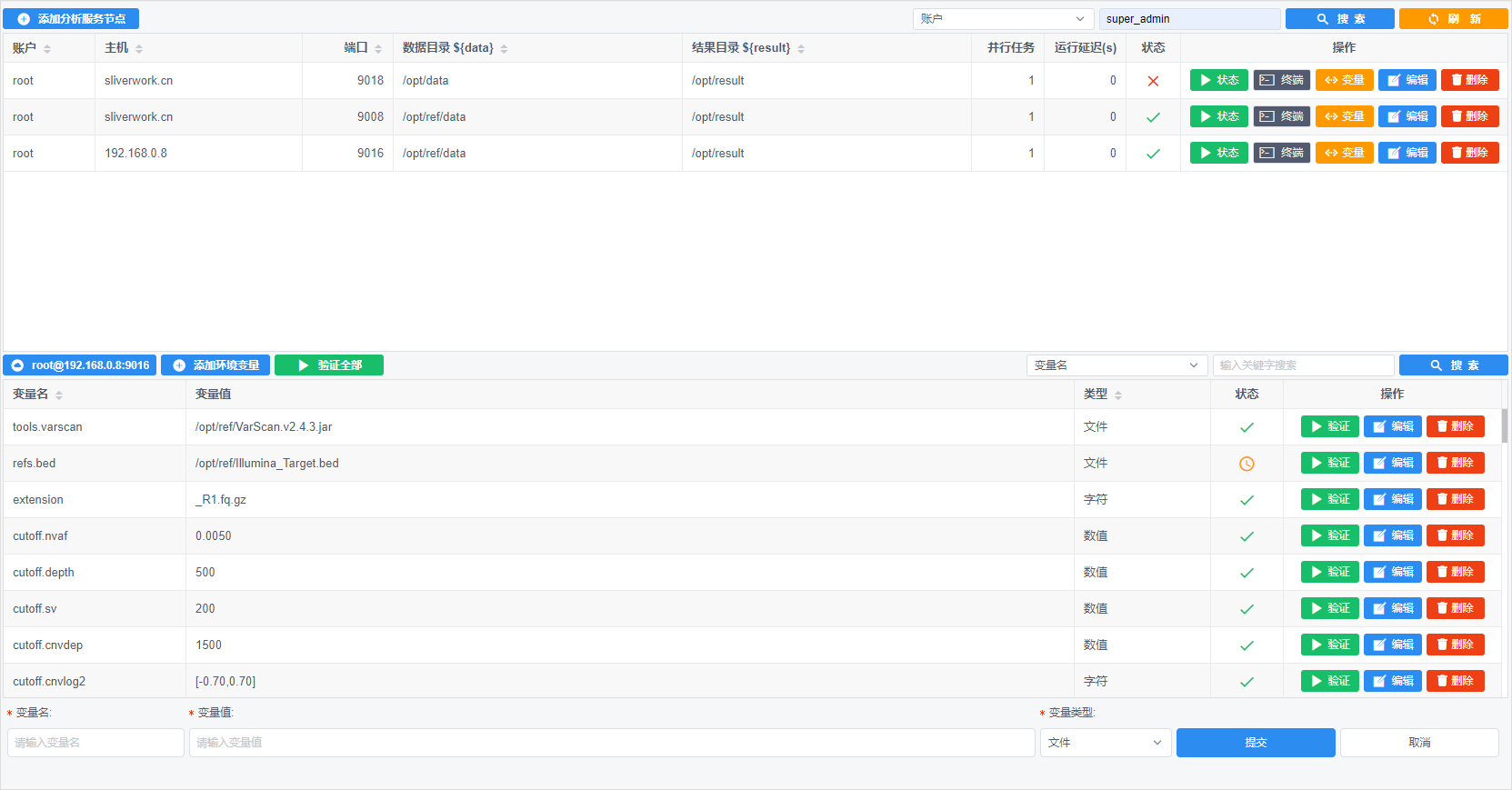
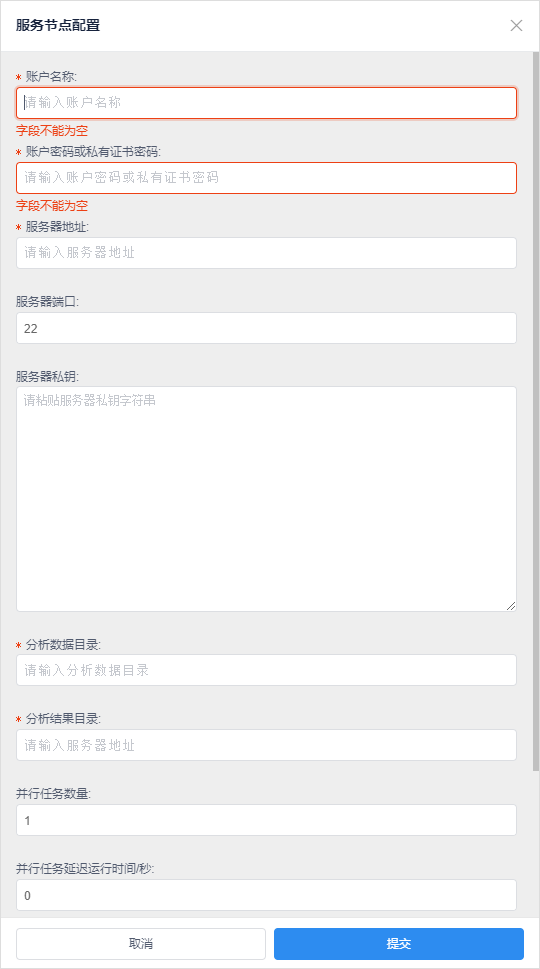
首先这里实现了,服务器账户信息的管理,账户、主机名、端口、密钥、密码,这些信息为了保证安全,需要二次加密,不能将密码明文保存在数据库中,一旦泄漏危害巨大
针对分析流程,按照约定定义了两个变量:${data}数据输入目录,${result}输出目录
考虑到并行运算,这里设置了该账户可以并行运行的任务数量,已经连续运行任务的最小时间间隔。
前文中,针对pipeline里的变量,每个服务器账户对应一组变量,彼此独立,互相隔离。
针对服务器状态,提供状态按钮来验证是否符合要求。网络状态、变量值是否符合要求
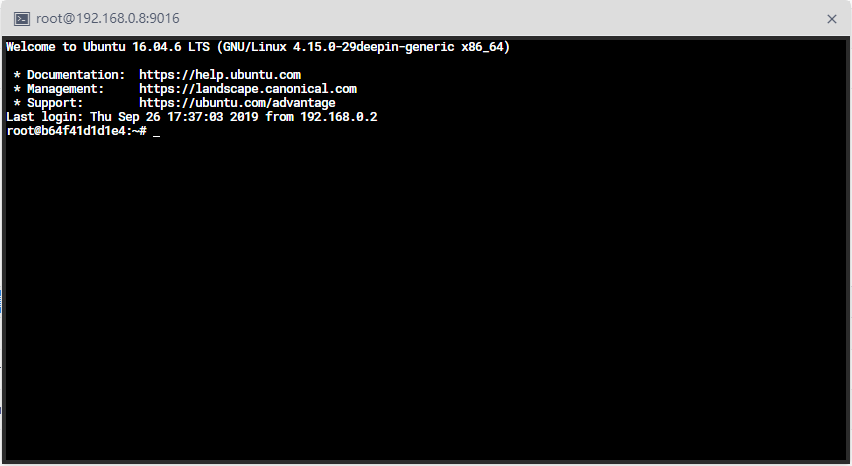
Web终端应急操作,可以点击终端按钮直接打开shell,手动操作,见下图:
运行的方式:
之前系统设计时所做的准备:
通过图形化设计之后获得的pipeline脚本
对应于服务器账户信息中的变量
录入系统的样本信息:样本编号,${sn} Run ID ${id}等等
通过将保存的shell脚本,将脚本变量用以上信息替换为实际需要运行的脚本,通过远程连接发送指令在服务器上运行
运行的过程:状态监控,结果的判断
发送完脚本,服务器端运行状态需要和控制端保持连接,监控运行状态,获取运行输出。
运行完成后服务器端推送信息到控制端,判断是否符合要求,输出文件是否存在
运行失败后服务器端推送信息到控制端,显示错误信息,错误日志,便于生信开发人员查找错误
统计每一个分析步骤的运行时间,便于统计分析
运行的结果:
如果需要获取分析结果文件的,这时候需要将该文件下载至本系统指定目录中。
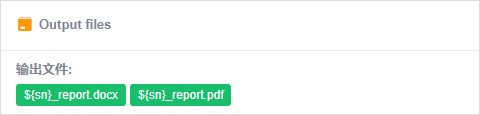
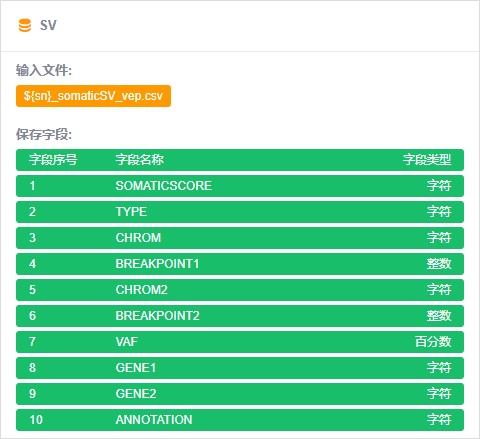
如果需要将分析结果vcf,csv等格式文件保存于数据库,按照前文中,pipeline图形化中设计格式,读取文件保存于系统数据库中。
收集标准化的数据,累积数据,为以后数据挖掘,回归分析做好准备
欢迎回复讨论或者加入QQ群:853718264
- 发表于 2019-09-27 14:23
- 阅读 ( 3508 )
- 分类:软件工具
