基因组去哪儿了
在国庆节前后,又有很多基因组文章发表出来。大家可能会诧异,我们并没有发现啊。只是看到了榴莲的基因组啊。是的,没错,最近的基因组文章可能已经发不了那么高了,(榴莲,NG)现在的基因组文章基本也就是5-10分的区间。
国庆节的大量的分母基因组文章发在了gigascience上。今天跟大家解读下发在gigascience上的三篇基因组文章:大额牛、椰子和人参。
随着测序数据的增加和成本的降低,测序数据的盘活,比如弄个数据库,可能会成为新的热点3-10分哦。
一、大额牛
1、摘要
牛在机械化不发达的地区仍是主要的劳动力,而在牛郎织女的神话故事中的老牛起至关重要的角色。
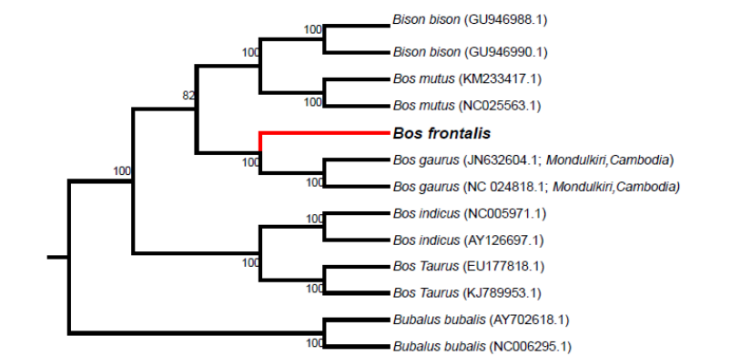
最近由昆明动物所研究发表一篇大额牛基因组文章,大额牛是我国唯一的半野生半家养的珍惜牛种,仅分布于云南省以及印度阿萨姆邦、东孟加拉和与缅甸北部钦邦。大额牛(2n=58)的染色体数目、形态和结构不同于黄牛(2n=60)和野牛(2n=56),以下为染色体形态图。

2、方法
利用高深度的二代数据进行组装,构建16个不同插入片段的文库(170bp~20Kb),共测350.38Gb的原始数据,经过滤后有276Gb的数据用于后续组装。
3、研究结果
1)基因组组装、注释
利用小文库数据(170bp和450bp)评估基因组大小约3.15Gb,通过Platanus软件组装得到2.85Gb,Contig N50为14.4Kb,Scaffold N50约2.74Mb,与已发表的黄牛和牦牛大小相似。通过BUSCO评估在4104个脊椎动物基因中有93%可以预测到,291个没有预测到,整体来说组装效果不错。
预测到的转座元件占基因组40.43%,基于同源物种牛、狗、人、小鼠和羊以及从头预测方法,AUGUSTUS、Genescan和GlimmerHMM,接下来用GLEAN整合以上结果得到26,667个编码基因,2,357个rRNA、29,821个tRNA、16,305个miRNA和1,380个snRNA。其中有97.18%可以注释到Kegg、GO等数据库。
2)系统发育分析和发散时间估计
通过与黄牛、牦牛、欧洲野牛、野牛、瘤牛和水牛等近缘物种进行比较构建进化树和分化时间,结果如图
二、椰子基因组草图
1、摘要
椰子作为重要热带水果和油料作物,在世界上93个国家都有分布,被人们广泛种植的主要有8-10年的“Tall”和4-6年的“Dwarf”两种。椰肉和椰汁那是即解渴又能充饥,各种荒岛求生节目中椰树的上场率也是非常高。
最近有海南大学等就对“Hainan Tall”(2n=32)进行组装分析。

2、方法
同样利用高深度的二代数据进行组装,构建不同梯度插入片段的文库,170bp~40Kb。总共测得714.67Gb的原始数据,经过一些列过滤后剩余419.08Gb的高质量数据用于后续组装。
3、研究结果
1)基因组组装、注释
利用209.38Gb的小文库数据预测基因组大小约2.42Gb,同时发现该物种属于高重复低杂合的类型。利用SOAdenovo2软件组装得到2.20Gb基因组序列,Contig N50为72.64Kb,Scaffold N50为418.06Kb,这个可能由于重复太高导致Scaffold的指标偏短。利用57,304条unigenes(来自三个不同组织的转录本序列)有96.78%能覆盖组装基因组序列,同时BUSCO评估结果显示1440个植物基因中有94.2%预测的到,5.8%没有找到。总的来看,组装结果还是可以。
预测重复序列占椰子基因组的74.48%。采用三种策略从头、同源和转录组,之后将同源和从头预测的结果进行GLEAN整合,最后整合GLEAN的结果和转录组预测结果得到28,039个基因,虽然预测基因数据少于同源其他物种,但进行BUSCO的结果要优于其他物种,说明这个预测结果准确性更高。其中有89.41%的基因能注释到KEGG、GO等数据库。
2)比较基因组分析
通过OrthoMCL分析,有79.80%的基因被分成14,411个基因家族,其中282个基因家族为本物种所特有。
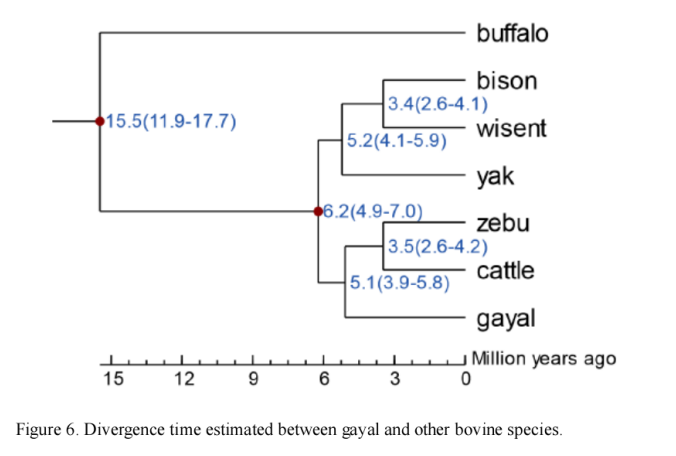
利用247个单拷贝基因进行进化树构建及化石时间,结果如下图

接下来有分析Na+/H+ antiporters,在拟南芥中,反转录基因的功能已被证实,该基因家族被细分为十三个不同的功能基团,涉及Na+/H+ antiporters的三个功能簇,其中有一些与耐盐性有关。结果图如下
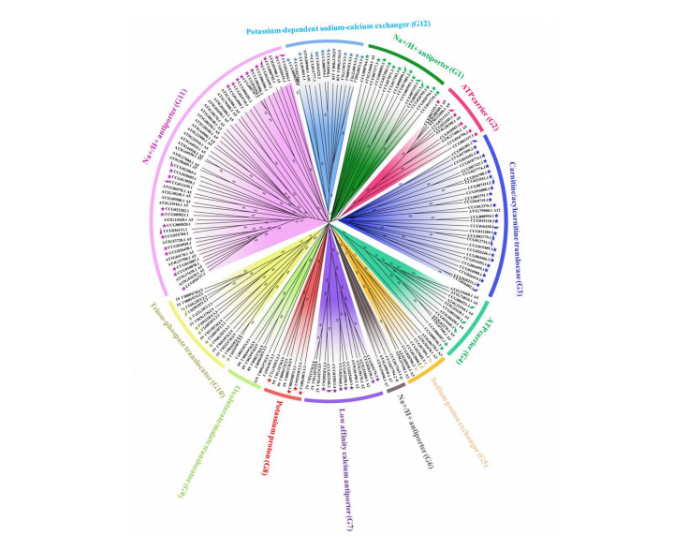
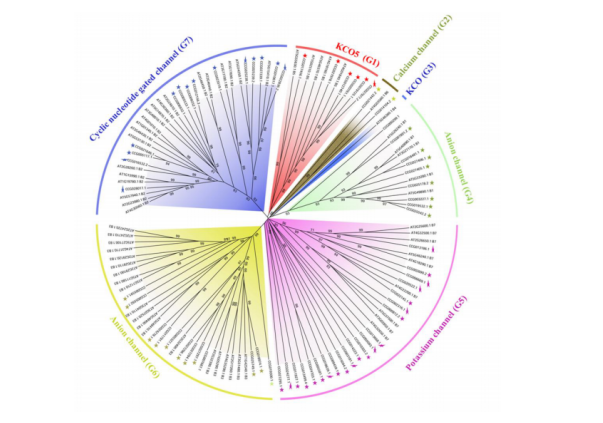
之后有分析基因组中的离子通道基因,67个相关基因被确定,详细结果展示图如下
三、人参基因组
1、摘要
人参数千年来被认为重要的传统重要,但关于人参的背景了解比较少,一部分原因是物种基因组比较大,基因结构比较复杂,小编的经验也是这种跟中草药相关的物种都是比较不好做。其主要分布在我国东北、朝鲜等,东北话棒槌讲的就是人参。小编小时候听过一些人参的神奇故事。
言归正题,该物种基因组有中国中医研究院中药研究所等进行研究。
2、材料
虽然现在PacBio、Nanopore等趋近普遍,但这篇文章还是用NGS数据进行组装。
这个选取四年生的低杂合高品质个体,构建五个文库,插入片段由250bp~10Kb,通过HiSeq X-Ten平台共测391.46Gb原始数据,在进行过滤接头和低质量后剩余315.93Gb的高质量数据用于后续组装。转录组数据是有22个样品数据,其中13个已公开。
3、结果
1)基因组组装、注释
初步组装基因组大小约3.43Gb,Contig N50约21.98Kb,Scaffold N50约108.71Kb,将250bp和500bp的高质量数据回比到组装基因组序列的效率分别为99.77%和99.95%,由于小文库测序深度较高,也可说明组装基因序列很完整(没有测到的区域就没法评估了)。利用75,878条转录本序列(由转录组数据通过Trinity软件进行组装得到)比对到基因组序列的比例达到97.76%,也是说明基因区组装比较完整,通过BUSCO进一步评估,98.19%的序列被预测出来,整体来说组装准确性非常高。
组装基因组中重复序列比例占到62%以上,其中Ty3/Gypsy占比最高。通过从头预测和MAKER两种方式预测得到42,006个编码基因,这里边有88%的基因有转录组数据支持,95.6%可以注释到Nr数据库,73.47%注释到GO和68.39%注释到KEGG等数据库,488个P450基因。
2)比较基因组分析
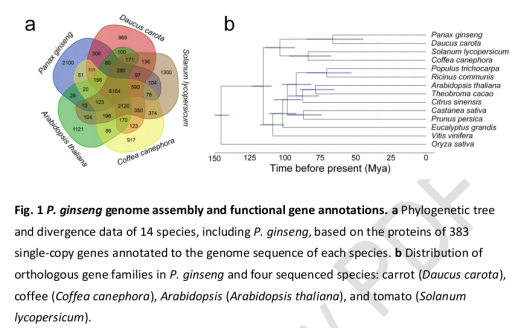
与13个其他植物进行基因家族分析,75%的基因被分成12,231个基因家族,其中1,648个家族为人参所特有。
利用找到383个单拷贝基因构建进化树,大约在66 Myr ago进行分化。
3)人参根代谢和转录组
人参有效成分主要在其根部,所以也是作者重点研究部分,通过DESI-MS阐明人参皂苷的空间结构,如图
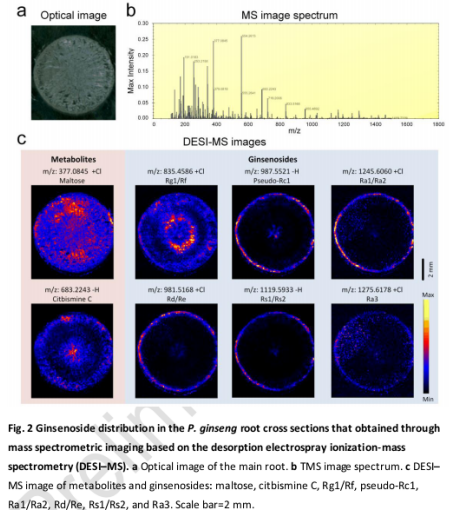
34,000个基因有转录组数据支持,其中27,450个在三个部位进行表达,7,456个在任何组织都没有发现。
之后又进行研究人参皂苷的保守生物合成途径和人参HMGR(PgHMGR)家族的序列分析以及UGTs分析,进行阐明人参药效机制。
编后语
目前大家研究的这些基因组也是越来越接近人们生活,但是这些对于外行来说还是比较难以理解,那么怎么能通俗易懂将这些故事讲给大家也是科研工作者后续要努力的方向,小编觉得以网站形式公开是一个比较不错的方法。
- 发表于 2017-10-14 10:57
- 阅读 ( 8713 )
- 分类:基因组学