R语言可以这么玩 |可视化中文分词和词频统计!~
小蟹君今天又要给大家介绍R的新玩法。中文分词!中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
我们用R语言实现中文文档的分词,统计各个词语的频数,以及最后用图片的形式呈现出来。
首先需要在R中安装rjava(该包要求电脑上已经安装java并配置好java环境)、RWordseg和wordcloud2包,前两个包用于分词,后一个包用于生成词云图。
我们选取的文档为俄罗斯作家索尔仁尼琴的小说作品《癌症楼》,从网上下载了txt格式的文档。因为这本小说内容涉及到一些医学专业词汇,故我们需要首先从本地导入医学专用词库。词库可以在网上预先下载下来。
#导入本地词库
installDict("..\\医学词汇大全【官方推荐】.scel","yixue")
installDict("..\\肿瘤形态学编码词库1.scel","zhongliu")
小说的中文分词还需注意小说中的人物名很可能无法被机器识别出来,故我们需要手动向词典中添加这些人名词,使用到了insertWords()函数:
#向词典中添加人名
insertWords(c("科斯托格洛托夫","帕维尔","尼古拉耶维奇","鲁诺夫","伊丽莎白","阿纳托利耶夫娜","舒卢宾","艾哈迈占","费得拉乌","董佐娃","瓦季姆","普罗什卡"),save=TRUE)
随后,我们可以对文档进行一些预处理,以提高分词的准确率。处理方法包括剔除英文字母、数字、空格、标点符号等。预处理过后,调用RWordseg包中的segmentCN函数便可实现分词。《癌症楼》分词后部分结果如下:
[1] "癌症" "楼" "作者" "索" "尔" "仁" "尼"
[8] "琴" "第一章" "根本" "不" "是" "癌" "癌症"
[15] "楼" "也" "叫做" "13号" "楼" "帕维尔" "尼古拉耶维奇"
[22] "鲁" "萨" "诺" "夫" "从来不" "迷信" "也"
[29] "不" "可能" "有" "迷信" "思想" "但是" "当"
[36] "他" "看到" "为" "他" "开" "的" "住院"
[43] "许可证" "上" "写" "着" "13号" "楼" "的"
[50] "时候" "他" "的" "心" "不知" "为什么" "却"
[57] "为" "之" "一" "沉" "这" "是" "很"
[64] "不" "明智" "的" "就" "该" "把" "什么"
. . .
再用table函数统计词频,得到部分结果如下:
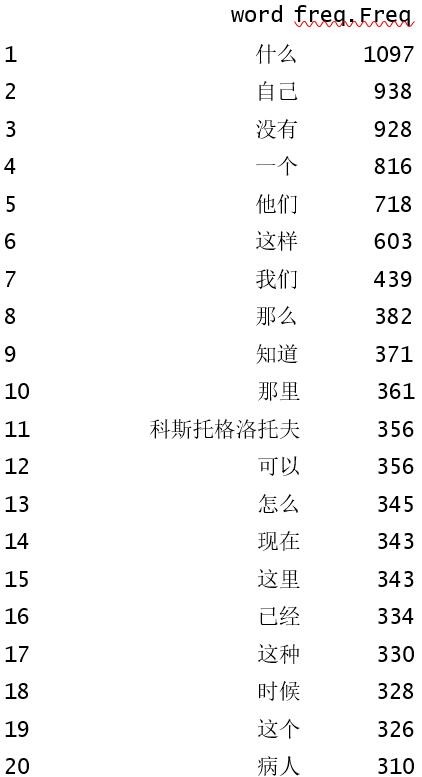
...
可视化部分要用到wordcloud2包,该包支持导入本地的图片。wordcloud2包中自带一张小鸟图,可以直接被调用。

▲萌萌哒的小鸟~
我们也可以自行从网上下载一些喜欢的图片作为词云的背景。小蟹君一直很喜欢超级英雄,于是用了下载蜘蛛侠的图片作为背景哦~可视化结果如下:

▲还有帅气的蜘蛛侠~
哈哈哈,是不是很炫酷呢?
如上面所显示的,中文文档的分词与词频统计可以将一篇文章拆解为一个个单独的词语。我们可以通过浏览出现频率高的词大致得知文章的重点内容,过滤掉许多无用的信息,省下了阅读整篇文档的时间。词云将分词结果可视化展现了出来,频率较高的单词或词语会以较大的形式呈现出来,而频率越低的单词或词语则会以较小的形式呈现。词云制作时,我们可以自由地选择背景图和背景文字。
大家不妨来试一试自己喜爱的背景,制作有趣的词云图吧!
- 发表于 2017-04-24 15:33
- 阅读 ( 8074 )
- 分类:编程语言
